Code
!pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local
%load_ext autoreload
%autoreload 2 ![]()
“Efficiency is the bridge to intelligence.” - Alan Turing
Since the emergence of Transformers in 2017, large language models like BERT and GPT have been continuously developed, opening a new era for artificial intelligence with their remarkable performance. However, behind these successes lay fundamental limitations of the Transformer architecture and efforts to overcome them. To address issues such as computational complexity and limitations in handling long texts, continuous improvements and structural proposals were made. Especially after 2019, as model sizes rapidly increased, research on efficiency became more active.
Major Changes by Period:
This chapter examines the limitations of Transformers and discusses various methods to address these issues in detail.
Challenge: How can we reduce the computational complexity and memory usage of Transformer models to process longer contexts and train larger models?
Researcher’s Dilemma: While Transformer models performed exceptionally well, their computational costs were enormous. The attention mechanism, in particular, had a complexity proportional to the square of the sequence length, severely limiting model scalability. Researchers had to find ways to maintain the core functionality of attention while increasing computational efficiency. This wasn’t about simply reducing model size but seeking innovative solutions at the algorithmic and hardware levels. It was akin to building a large structure while minimizing the weight and cost of each brick.
The quadratic complexity of attention operations, limited context length, and memory efficiency issues were major obstacles to model expansion. These limitations became crucial factors in determining the direction of Transformer development.
During the process of scaling up Transformer models, the complexity of attention operations, particularly the complexity proportional to the square of the sequence length, was a significant problem.
Analysis of Attention Operation Complexity:
\(Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\)
Let’s examine the actual code performance and memory usage.
!pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local
%load_ext autoreload
%autoreload 2from dldna.chapter_09.complexity_benchmark import measure_attention_complexity, plot_complexity_analysis, measure_attention_complexity_gpu
seq_lengths = [100, 500, 1000, 2000, 4000, 8000, 10000, 15000]
results = measure_attention_complexity(seq_lengths=seq_lengths)
print("\n=== Complexity Analysis of Attention Operation ===")
print("\nMemory usage and execution time by sequence length:")
print("Length\t\tMemory (MB)\tTime (seconds)")
print("-" * 40)
for seq_len, mem, time_taken in results:
print(f"{seq_len}\t\t{mem:.2f}\t\t{time_taken:.4f}")
# Visualize with a graph
plot_complexity_analysis(results)
=== Complexity Analysis of Attention Operation ===
Memory usage and execution time by sequence length:
Length Memory (MB) Time (seconds)
----------------------------------------
100 18.75 0.0037
500 96.58 0.0388
1000 317.00 0.1187
2000 1119.00 0.4228
4000 4188.14 1.6553
8000 16142.53 6.5773
10000 25039.31 10.2601
15000 55868.54 25.1265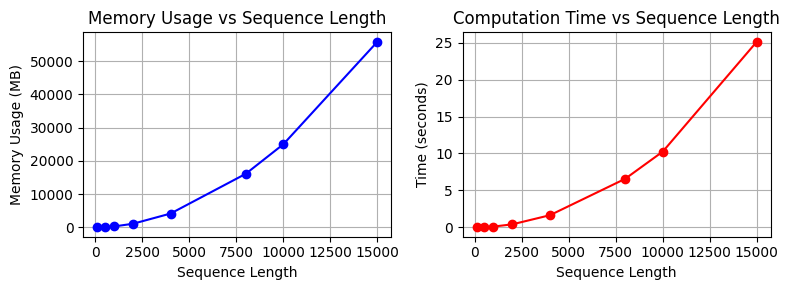
In actual transformer models, this operation is repeated in multiple layers, and as the batch size increases, the amount of computation increases even more.
# Compare theoretical complexity with actual measurements
print("\n=== Comparison of Theoretical Complexity and Actual Measurements ===")
base_seq = seq_lengths[0]
base_mem = results[0][1]
base_time = results[0][2]
print("\nTheoretical vs Actual Growth Rate (Base: First Sequence Length)")
print("Length Theoretical(N²) Actual Memory Actual Time")
print("-" * 60)
for seq_len, mem, time_taken in results:
theoretical = (seq_len/base_seq) ** 2
actual_mem = mem/base_mem
actual_time = time_taken/base_time
print(f"{seq_len:6d} {theoretical:10.2f}x {actual_mem:10.2f}x {actual_time:10.2f}x")
=== Comparison of Theoretical Complexity and Actual Measurements ===
Theoretical vs Actual Growth Rate (Base: First Sequence Length)
Length Theoretical(N²) Actual Memory Actual Time
------------------------------------------------------------
100 1.00x 1.00x 1.00x
500 25.00x 5.15x 8.05x
1000 100.00x 16.91x 32.49x
2000 400.00x 59.71x 124.52x
4000 1600.00x 223.34x 474.71x
8000 6400.00x 860.92x 1882.04x
10000 10000.00x 1335.43x 2976.84x
15000 22500.00x 2979.67x 7280.40xThe quadratic complexity is particularly problematic for large models like GPT-3. It has led to many limitations, including document length limits and batch size limits during training. This has been a major motivation for developing efficient attention mechanisms.
Early attempts to solve the quadratic complexity problem of transformers have proceeded in three main directions.
Sliding Window Attention
Compute attention only within a fixed-size window.
def sliding_window_attention(q, k, v, window_size):
"""Sliding window attention"""
batch_size, seq_len, dim = q.shape
attention_weights = np.zeros((batch_size, seq_len, seq_len))
for i in range(seq_len):
start = max(0, i - window_size // 2)
end = min(seq_len, i + window_size // 2 + 1)
scores = np.matmul(q[:, i:i+1], k[:, start:end].transpose(0, 2, 1))
attention_weights[:, i, start:end] = softmax(scores, axis=-1)
return np.matmul(attention_weights, v)This method reduces the complexity to \(O(N \cdot w)\) (w: window size).
Sparse Attention Patterns
Sparse attention patterns are a way of calculating only some relationships according to specific patterns, rather than calculating the relationship between all token pairs. For example, when there is a sequence composed of 10 tokens, regular attention calculates all 100 relationships (10×10), but sparse attention calculates only some of them.
def sparse_block_attention(q, k, v, block_size):
"""Block sparse attention
Example: seq_len=8, block_size=2
Process the sequence in 4 blocks of 2 tokens each
Block 1 (0,1), Block 2 (2,3), Block 3 (4,5), Block 4 (6,7)
"""
batch_size, seq_len, dim = q.shape # e.g., (1, 8, 64)
num_blocks = seq_len // block_size # e.g., 8/2 = 4 blocks
attention_weights = np.zeros((batch_size, seq_len, seq_len))
for i in range(num_blocks):
# e.g., when i=0, process Block 1 (0,1)
start_q = i * block_size # 0
end_q = (i + 1) * block_size # 2
for j in range(num_blocks):
# e.g., when j=0, attention with Block 1 (0,1)
start_k = j * block_size # 0
end_k = (j + 1) * block_size # 2
# Calculate attention between tokens in Block 1 (0,1) and Block 1 tokens (0,1)
scores = np.matmul(
q[:, start_q:end_q], # (1, 2, 64)
k[:, start_k:end_k].transpose(0, 2, 1) # (1, 64, 2)
) # Result: (1, 2, 2)
# Store weights block by block
attention_weights[:, start_q:end_q, start_k:end_k] = softmax(scores, axis=-1)
# Generate the final context vectors
return np.matmul(attention_weights, v)Low-rank approximation is a method of expressing large matrices as the product of smaller matrices. For example, in a sentence with 10 tokens, regular attention calculates 10×10=100 relationships, whereas low-rank approximation represents it as the product of two matrices, 10×4 and 4×10 (rank=4). Thus, it achieves similar results with 80 operations instead of 100.
def low_rank_attention(q, k, v, rank):
"""Low-rank attention
Example: seq_len=10, dim=64, rank=16
Project Q, K from 64 dimensions to 16 dimensions to reduce computation
"""
batch_size, seq_len, dim = q.shape # e.g., (1, 10, 64)
# Create projection matrices to project from 64 dimensions to 16 dimensions
projection_q = np.random.randn(dim, rank) / np.sqrt(rank) # (64, 16)
projection_k = np.random.randn(dim, rank) / np.sqrt(rank)
# Project Q, K to 16 dimensions
q_low = np.matmul(q, projection_q) # (1, 10, 16)
k_low = np.matmul(k, projection_k) # (1, 10, 16)
# Calculate attention in the lower dimension (operations on 10x16 matrices)
attention = np.matmul(q_low, k_low.transpose(0, 2, 1)) # (1, 10, 10)
attention_weights = softmax(attention, axis=-1)
# Generate the final context vectors
return np.matmul(attention_weights, v) # (1, 10, 64)This method was able to reduce the complexity to \(O(N \cdot r)\). Here, r is the rank used for approximation. Let’s calculate the efficiency of each method.
from dldna.chapter_09.attention_complexity_examples import calcualte_efficieny
calcualte_efficieny()Original input shape: (2, 8, 4)
1. Sliding Window Attention
Output shape: (2, 8, 4)
Output of the first batch, first token: [-0.78236164 0.22592055 -1.03027549 1.13998368]
2. Block Sparse Attention
Output shape: (2, 8, 4)
Output of the first batch, first token: [-1.66095776 0.76700744 -0.45857165 -0.77422867]
3. Low-Rank Attention
Output shape: (2, 8, 4)
Output of the first batch, first token: [ 0.51121005 0.66772692 -0.77623488 -0.0323534 ]
Memory Usage Comparison (Relative Size):
Full Attention: 64
Sliding Window: 32
Block Sparse: 64
Low Rank: 32However, early attempts had limitations such as information loss, implementation complexity, and performance degradation. Google focused more on low-rank approximation, while Microsoft developed sparse patterns. These early approaches later evolved into hybrid methods that utilize both sparsity and low-rank properties.
Another important limitation is memory efficiency. Especially for large language models, there are the following memory burdens.
First, there is a memory burden due to the KV cache. In the self-recurrence generation process, the Key and Value values of the previous time step must be stored, which increases linearly with the sequence length. For example, in the case of GPT-3, about 16MB of KV cache is required for each layer when processing 2048 tokens. Second, there are memory requirements during backpropagation. The transformer stores intermediate activation values (activation value) - intermediate calculation results that occur in the attention layer (Q, K, V transformation values, attention scores, softmax outputs, etc.). This burden increases rapidly as the number of layers increases. In the case of BERT-large, about 24GB of memory was required for a single batch. Third, there is the memory usage of the attention operation itself. The attention score matrix has a size proportional to the square of the sequence length, which becomes a serious bottleneck when processing long documents.
To address these memory issues, optimization techniques such as gradient checkpointing, mixed precision training, and FlashAttention have been proposed.
To overcome the computational complexity and memory efficiency limitations of transformers discussed in sections 9.1.1 and 9.1.2, researchers have developed various techniques to improve efficiency and scalability. These techniques have made transformer models more powerful and practical, having a significant impact on the field of deep learning as a whole.
This chapter provides an overview of the timeline of transformer evolution and introduces major technologies and models for each period as follows:
Table: Timeline of Transformer Evolution, Major Models/Technologies, Key Contents, Deep Learning DNA | Section | Period (Approx.) | Main Models/Technologies | Core Content and Description | Deep Learning DNA | |———|————-|————————|————————-|———————————————–| | 9.1 | 2017-2018 | Transformer | Introduced Attention mechanism to overcome limitations of existing RNN, CNN.
Innovation in sequence-to-sequence models | Attention Mechanism: Proposed a new method to focus on important parts of the data | | 9.2 | 2019-2020 | Performer, Sparse Transformer, Longformer
Reformer, BigBird | Software approaches to reduce computational complexity.
Linear Attention: Approximated attention operations (Performer).
Sparse Attention: Applied attention only to some token pairs (Sparse Transformer, Longformer).
Local-Global Attention: Combined local and global information (Reformer, BigBird) | Efficient Attention: Efforts to maintain the advantages of Attention while reducing computational complexity.
Long-range Dependencies: Structural improvements to effectively handle long contexts | | 9.3 | 2021-2022 | FlashAttention, MQA, GQA, PagedAttention, vLLM | Hardware and software approaches to improve memory efficiency.
FlashAttention: Utilized GPU memory hierarchy, tiling, and block processing.
MQA/GQA: Optimized queries, shared Key/Value.
KV Cache Optimization: PagedAttention, vLLM | Hardware Optimization: Efficient operation methods considering GPU memory structure.
Parallel Processing: Increased operational efficiency through query sharing | | 9.4 | 2022-2023 | Claude-2, LongLoRA, Constitutional AI, RLHF,
RLAIF, Hierarchical Attention, Recurrent Memory | Scalable and Specialized architectures.
Long Context: Hierarchical attention, Recurrent Memory Transformer.
Ethics/Safety: Rule-based attention, reinforcement learning-based adjustment | Long Context: Evolution of model structures to handle longer contexts.
Fine-tuning: Methods to adjust models for specific purposes | | 9.5| 2022-2023 | Efficient Encoder (FlashAttention-based) | Text classification (AG News), FlashAttention, Pre-LN, Gradient Checkpointing, Mixed Precision Training | Implementation: Utilization of efficient encoders | | 9.6| 2023 | Mistral, Efficient Decoder (GQA, Sliding Window Attention-based) | Analysis of Mistral model: GQA, Sliding Window Attention, RoPE, KV cache, etc.
Application examples: Number-text conversion, natural language-SQL conversion (code generation), text-code generation. | Implementation: Efficient decoder architectures | | 9.7| 2024 | Gemma | Open models for efficiency and accessibility | Open Models: Improved research and development accessibility | | 9.8 | 2024 | Phi-3 | Small but efficient LLM | Implementation: Powerful SLM (Small Language Model) | The composition of this chapter is as follows.
From 2019 to 2020, various attempts were made to reduce the computational complexity of transformers. In particular, the advancements led by Google Research and DeepMind during this period greatly improved the efficiency of attention operations.
In early 2020, the Google Research team successfully reduced the complexity of attention from O(N²) to O(N) through FAVOR+ (Fast Attention Via positive Orthogonal Random features). FAVOR+ is the core mechanism of the Performer model and was the first method to make long-sequence processing practically possible.
The key idea behind FAVOR+ starts with the kernel trick. The kernel trick reinterprets softmax attention as follows:
\(Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d}})V\)
This can be approximated using a positive-valued kernel function φ(x) as follows:
\(Attention(Q,K,V) ≈ \frac{\phi(Q)\phi(K)^TV}{\phi(Q)\phi(K)^T\mathbf{1}}\)
The core idea is to reinterpret softmax attention in fractional form and use the kernel function φ(x) to rearrange the order of matrix multiplications, similar to changing \((a \times b) \times c\) to \(a \times (b \times c)\).
import numpy as np
def kernel_attention(Q, K, V, feature_dim=256): # Q: (seq_len, d_model) K: (seq_len, d_model) V: (seq_len, d_model)
# 1. Generate random projection matrix
projection = np.random.randn(Q.shape[-1], feature_dim) / np.sqrt(feature_dim)
# projection: (d_model, feature_dim)
# 2. Project Q, K to lower dimension and apply ReLU
Q_mapped = np.maximum(0, np.dot(Q, projection)) # phi(Q)
# Q_mapped: (seq_len, feature_dim)
K_mapped = np.maximum(0, np.dot(K, projection)) # phi(K)
# K_mapped: (seq_len, feature_dim)
# 3. Calculate numerator: phi(Q)phi(K)^TV
KV = np.dot(K_mapped.T, V) # (feature_dim, V_dim)
# KV: (feature_dim, d_model)
numerator = np.dot(Q_mapped, KV) # (seq_len, V_dim)
# numerator: (seq_len, d_model)
# 4. Calculate denominator: phi(Q)phi(K)^T1
K_sum = np.sum(K_mapped, axis=0, keepdims=True) # (1, feature_dim)
# K_sum: (1, feature_dim)
denominator = np.dot(Q_mapped, K_sum.T) # (seq_len, 1)
# denominator: (seq_len, 1)
# 5. Final attention output
attention_output = numerator / (denominator + 1e-6)
# attention_output: (seq_len, d_model)
return attention_output
# Example usage
seq_len, d_model = 1000, 64
Q = np.random.randn(seq_len, d_model)
K = np.random.randn(seq_len, d_model)
V = np.random.randn(seq_len, d_model)
# Calculate attention with O(N) complexity
output = kernel_attention(Q, K, V)
print(output)[[-0.00705502 -0.01553617 -0.01976792 ... -0.00906909 0.02983678
0.0424082 ]
[-0.00201811 -0.01741265 -0.00458378 ... -0.02578894 0.04247468
0.03793401]
[-0.01130314 -0.02011524 -0.00962334 ... -0.01348429 0.04382548
0.01967338]
...
[ 0.00180466 -0.01818735 -0.02244794 ... -0.01978542 0.03202302
0.03887265]
[-0.00421543 -0.01679868 -0.00537492 ... -0.00314385 0.05363415
0.03304721]
[ 0.00107896 -0.02042812 -0.01947976 ... -0.00557582 0.04534007
0.04408479]]The three core changes introduced by FAVOR+ are as follows:
The processing steps of FAVOR+ are as follows:
import numpy as np
def favor_plus_attention(q, k, v, feature_dim=256):
"""FAVOR+ attention implementation
Args:
q: Query tensor (batch_size, seq_len, d_model)
k: Key tensor (batch_size, seq_len, d_model)
v: Value tensor (batch_size, seq_len, d_model)
feature_dim: The number of dimensions of the low-dimensional feature space
"""
d_model = q.shape[-1]
# 1. Generate an orthonormal random projection matrix
random_matrix = np.random.randn(d_model, feature_dim)
q_orth, _ = np.linalg.qr(random_matrix)
projection = q_orth / np.sqrt(feature_dim) # (d_model, feature_dim)
# 2. Project Q, K to the low-dimensional feature space and apply ReLU
q_prime = np.maximum(0, np.matmul(q, projection)) # (batch_size, seq_len, feature_dim)
k_prime = np.maximum(0, np.matmul(k, projection)) # (batch_size, seq_len, feature_dim)
# 3. Calculate linear-time attention
# Use einsum to perform matrix multiplication while maintaining the batch dimension
kv = np.einsum('bsf,bsd->bfd', k_prime, v) # (batch_size, feature_dim, d_model)
# Calculate the numerator
numerator = np.einsum('bsf,bfd->bsd', q_prime, kv) # (batch_size, seq_len, d_model)
# Calculate the denominator (normalization term)
k_sum = np.sum(k_prime, axis=1, keepdims=True) # (batch_size, 1, feature_dim)
denominator = np.einsum('bsf,bof->bso', q_prime, k_sum) # (batch_size, seq_len, 1)
# 4. Calculate the final attention output
attention_output = numerator / (denominator + 1e-6) # (batch_size, seq_len, d_model)
return attention_output
# Example usage
batch_size, seq_len, d_model = 2, 100, 512
q = np.random.randn(batch_size, seq_len, d_model)
k = np.random.randn(batch_size, seq_len, d_model)
v = np.random.randn(batch_size, seq_len, d_model)
output = favor_plus_attention(q, k, v)
print("Output tensor shape:", output.shape)Output tensor shape: (2, 100, 512)FAVOR+ has the following advantages:
Mathematical Foundation
The mathematical foundation of FAVOR+ lies in the Johnson-Lindenstrauss lemma. The key idea is that even when high-dimensional data is projected into a lower dimension, the distance relationship between the data is almost preserved. In other words, reducing 1000-dimensional data to 100 dimensions does not significantly change the relative distances between the data points.
The success of FAVOR+ led to the development of various linear attention models, including Linear Transformer and Linear Attention Transformer, which played a crucial role in processing long sequences.
In 2019, OpenAI introduced fixed sparse patterns through the Sparse Transformer. Instead of calculating the relationships between all token pairs, this method calculates only certain relationships based on specific patterns.
Sparse Transformer’s Fixed Patterns
The Sparse Transformer uses two main sparse patterns:
These patterns can be represented mathematically as follows:
\(Attention(Q,K,V) = softmax(\frac{QK^T \odot M}{\sqrt{d_k}})V\)
where M is the sparse mask matrix, and ⊙ denotes element-wise multiplication. The mask matrix indicates which token pairs to apply attention to (1) or not to apply (0).
This approach improved computational efficiency but had the drawback of having fixed patterns that were inflexible and unable to adapt to different contexts.
Longformer’s Local-Global Combination
In 2020, Allen AI proposed a more flexible sparse pattern through the Longformer. The Longformer uses a hybrid approach that combines local attention and global attention:
This method allows for a richer understanding of context by considering both local and global contexts simultaneously.
There is no original text to translate.
import numpy as np
def longformer_attention(q, k, v, window_size=3, global_tokens=[0]):
"""Longformer attention implementation
Args:
q, k, v: (batch_size, seq_len, d_model)
window_size: Size of the local attention window
global_tokens: List of token indices to perform global attention on
"""
batch_size, seq_len, d_model = q.shape
attention_weights = np.zeros((batch_size, seq_len, seq_len))
# 1. Local attention: sliding window
for i in range(seq_len):
# Calculate window range
window_start = max(0, i - window_size)
window_end = min(seq_len, i + window_size + 1)
window_size_current = window_end - window_start
# Calculate attention scores within the window
scores = np.matmul(q[:, i:i+1], k[:, window_start:window_end].transpose(0, 2, 1))
# scores: (batch_size, 1, window_size_current)
attention_weights[:, i:i+1, window_start:window_end] = scores
# 2. Global attention: specific tokens attend to all tokens
for global_idx in global_tokens:
# Calculate attention scores for global tokens
scores = np.matmul(q[:, global_idx:global_idx+1], k.transpose(0, 2, 1))
# scores: (batch_size, 1, seq_len)
attention_weights[:, global_idx:global_idx+1, :] = scores
attention_weights[:, :, global_idx:global_idx+1] = scores.transpose(0, 2, 1)
# 3. Apply softmax (row-wise)
attention_weights = np.exp(attention_weights) / np.sum(np.exp(attention_weights), axis=-1, keepdims=True)
# 4. Calculate the final output by applying weights
output = np.matmul(attention_weights, v) # (batch_size, seq_len, d_model)
return output
# Example usage
batch_size, seq_len, d_model = 2, 10, 64
q = np.random.randn(batch_size, seq_len, d_model)
k = np.random.randn(batch_size, seq_len, d_model)
v = np.random.randn(batch_size, seq_len, d_model)
output = longformer_attention(q, k, v, window_size=2, global_tokens=[0])
print(output)[[[-0.72195324 0.03196266 -0.06067346 ... 0.57106283 1.31438
0.63673636]
[-1.72619367 -0.39122625 0.91285828 ... -1.4031466 1.2081069
0.95934394]
[ 0.07427921 0.42596224 -0.44545069 ... 0.154228 0.37435003
-0.01884786]
...
[ 1.26169539 -0.58215291 2.00334263 ... 1.15338425 0.31404728
-1.33672458]
[ 0.96005607 0.39904084 0.5703471 ... -0.2168805 0.93570179
0.05680507]
[ 0.61648602 -0.12874142 1.09736967 ... 0.32421211 1.23082505
0.4141766 ]]
[[ 0.92762851 0.26334678 -0.81047846 ... -0.19186621 0.42534117
0.57313974]
[ 1.01307261 0.61571205 -1.26925081 ... -0.56016688 -0.19707427
2.49452497]
[-1.0071559 2.81291178 2.5010486 ... 1.63559632 -0.60892113
-1.40952186]
...
[-1.96615634 1.85881047 0.19361453 ... 1.21044747 -0.00772792
-0.68961122]
[ 0.09090778 1.94770672 -0.990489 ... -0.09841141 0.65195305
0.11634795]
[-2.43256801 1.66319642 0.23557316 ... 2.39325846 0.8750332
0.66295002]]]Block Sparse Matrix Operation Optimization
To efficiently implement the hybrid approach of Longformer, block sparse matrix operation optimization is necessary.
The sparse pattern-based approach reduced complexity to O(N log N) or O(N), but it had implementation complexities and difficulties in hardware optimization.
In early 2020, Google Research and Allen AI proposed a hybrid approach combining local-global attention. This was an attempt to address the information loss of linear attention and the implementation complexity of sparse patterns.
Reformer uses Locality-Sensitive Hashing (LSH) to efficiently cluster similar vectors. The core principle of LSH is as follows:
\(h(x) = \text{argmax}( [xR; -xR] )\)
where R is a random projection matrix, and similar vectors have a high probability of having the same hash value. Reformer follows these steps:
This method is efficient for processing long sequences but may suffer from information loss due to hash collisions.
BigBird combines three attention patterns to complement Reformer’s limitations.
This mixed strategy is expressed by the following formula:
\(Attention(Q,K,V) = softmax(\frac{QK^T \odot (M_{local} + M_{global} + M_{random})}{\sqrt{d_k}})V\)
where M is the mask matrix for each. This structure achieves O(N) complexity while maintaining BERT-level performance.
Influence of Hybrid Patterns
BigBird’s success demonstrated the potential of local-global approaches, significantly influencing modern transformer models.
From 2021 to 2022, the focus was on improving the memory efficiency of transformers. In particular, optimization considering the GPU memory hierarchy and efficient implementation of attention operations were notable. The methods of this period made it possible to implement large language models practically.
In 2022, Tri Dao’s research team at Stanford University proposed FlashAttention, which considers the GPU memory hierarchy. This was a hardware-centered improvement that fundamentally redesigned the memory access pattern of attention operations. FlashAttention significantly improved the training and inference speeds of transformer models, especially those processing long sequences, contributing greatly to the development of large language models. FlashAttention v2, announced in 2023, further optimized the original FlashAttention, achieving 2-4 times faster speeds.
The advantage of FlashAttention lies in its explicit consideration of the GPU’s memory hierarchy. GPUs have two types of memory: large but slow HBM (High Bandwidth Memory) and small but fast SRAM. HBM has a large capacity but slow access speed, while SRAM has a small capacity but very fast access speed. FlashAttention utilizes these characteristics.
This hardware-aware design significantly reduced memory access.
To achieve memory optimization, the tiling technique was introduced. Tiling is a hardware optimization technique that divides large matrices into small blocks suitable for SRAM and processes them.
This block processing strategy enabled the calculation of accurate attention results while minimizing memory bandwidth usage.
FlashAttention v2 added several low-level optimizations to maximize hardware utilization while maintaining the basic ideas of v1. It achieved 2-4 times speed improvement compared to v1 and showed particularly superior performance in processing long sequences. * Kernel Fusion: FlashAttention v2 integrated multiple operations of the attention mechanism, such as query, key, value transformations, attention score calculation, softmax, and weighted average calculation, into a single CUDA kernel. This minimized the number of times intermediate results were stored in and read from HBM, reducing memory bandwidth usage and improving speed. * Non-sequential Attention Head Processing: Unlike previous versions that processed attention heads sequentially, FlashAttention V2 processes them in parallel as much as GPU resources allow, reducing latency. * Cache-friendly Memory Layout: A data structure was designed to better fit the GPU cache line, such as storing data in column-major order. This reduced cache misses and improved data access speed. * Warp-level Parallelization: The 32 threads within a CUDA warp were utilized to process each part of the attention operation in parallel as much as possible. This maximized the use of the GPU’s SIMD characteristics and parallel processing capabilities, increasing calculation speed.
Through these comprehensive optimizations, FlashAttention v2 achieved up to 20 times better memory efficiency and 2-4 times faster speed than the existing PyTorch attention implementation in certain environments. The success of FlashAttention demonstrated the importance of algorithm design based on a deep understanding of hardware characteristics and became a key technology for large language models such as GPT-4 and Claude.
The official implementation of FlashAttention is provided as NVIDIA CUDA code. In PyTorch, it can be used through the flash-attn package, and it has also been integrated into the latest version of the Hugging Face transformers library.
In 2022, Google Research proposed Multi-Query Attention (MQA) through the PaLM model to improve memory efficiency from a software design perspective. Unlike FlashAttention’s hardware-centric optimization, this approach redesigns the attention structure itself to reduce memory usage.
The core of MQA is to modify the design so that all attention heads share the same Key and Value.
import numpy as np
def multi_query_attention(q, k, v, num_heads):
"""Multi-Query Attention implementation
Args:
q: (batch_size, seq_len, d_model)
k: (batch_size, seq_len, d_model)
v: (batch_size, seq_len, d_model)
num_heads: Number of heads
"""
batch_size, seq_len, d_model = q.shape
head_dim = d_model // num_heads
# 1. Convert K, V to single matrices shared by all heads
k_shared = np.dot(k, np.random.randn(d_model, d_model)) # (batch_size, seq_len, d_model)
v_shared = np.dot(v, np.random.randn(d_model, d_model)) # (batch_size, seq_len, d_model)
# 2. Generate Q differently for each head
q_multi = np.dot(q, np.random.randn(d_model, num_heads * head_dim)) # (batch_size, seq_len, num_heads * head_dim)
q_multi = q_multi.reshape(batch_size, seq_len, num_heads, head_dim) # (batch_size, seq_len, num_heads, head_dim)
# Transform k_shared to head_dim size
k_shared = np.dot(k_shared, np.random.randn(d_model, head_dim)) # (batch_size, seq_len, head_dim)
# 3. Calculate attention scores
scores = np.matmul(q_multi, k_shared.reshape(batch_size, seq_len, head_dim, 1))
# scores: (batch_size, seq_len, num_heads, 1)
# 4. Apply softmax
weights = np.exp(scores) / np.sum(np.exp(scores), axis=-1, keepdims=True)
# weights: (batch_size, seq_len, num_heads, 1)
# 5. Multiply V with weights
v_shared = np.dot(v_shared, np.random.randn(d_model, head_dim)) # Transform V to head_dim as well
v_shared = v_shared.reshape(batch_size, seq_len, 1, head_dim)
output = np.matmul(weights, v_shared)
# output: (batch_size, seq_len, num_heads, head_dim)
# 6. Concatenate heads and transform output
output = output.reshape(batch_size, seq_len, num_heads * head_dim)
output = np.dot(output, np.random.randn(num_heads * head_dim, d_model))
# output: (batch_size, seq_len, d_model)
return output
# Example usage
batch_size, seq_len, d_model = 2, 100, 512
num_heads = 8
q = np.random.randn(batch_size, seq_len, d_model)
k = np.random.randn(batch_size, seq_len, d_model)
v = np.random.randn(batch_size, seq_len, d_model)
output = multi_query_attention(q, k, v, num_heads)
print("Output tensor shape:", output.shape)/tmp/ipykernel_304793/3750479510.py:30: RuntimeWarning: overflow encountered in exp
weights = np.exp(scores) / np.sum(np.exp(scores), axis=-1, keepdims=True)
/tmp/ipykernel_304793/3750479510.py:30: RuntimeWarning: invalid value encountered in divide
weights = np.exp(scores) / np.sum(np.exp(scores), axis=-1, keepdims=True)Output tensor shape: (2, 100, 512)In early 2023, Meta AI proposed Grouped-Query Attention (GQA) to complement the limitations of MQA. GQA took an intermediate approach by grouping heads together, where each group shares K and V.
MQA and GQA, such query optimization structures, provide the following trade-offs.
| Structure | Memory Usage | Expressiveness | Speed | Implementation Complexity |
|---|---|---|---|---|
| Multi-Head Attention | N × H | High | Slow | Low |
| GQA | N × G | Medium | Medium | Medium |
| MQA | N | Low | Fast | Low |
(N: sequence length, H: number of heads, G: number of groups)
These structures have been widely adopted in modern large language models such as LLaMA, PaLM, and Claude, especially improving memory efficiency for long sequence processing.
In the second half of 2022, DeepMind, Anthropic, and the vLLM development team recognized the importance of KV cache management in the inference process of large language models. They proposed software and system-level memory optimization strategies that complement FlashAttention’s hardware-centric approach and MQA/GQA’s structural approach. This is particularly important when processing long conversations, generating long documents, or requiring high throughput.
PagedAttention and its implementation in vLLM are techniques inspired by operating system virtual memory and paging concepts to efficiently manage KV caches.
Problems with existing KV cache
Core idea of PagedAttention
Advantages of PagedAttention
vLLM: High-Performance Inference Engine using PagedAttention
vLLM is an open-source library that significantly improves the inference speed and throughput of large language models by utilizing PagedAttention as its core technology.
Continuous batching is a key technology for maximizing throughput in large language model services. PagedAttention and vLLM efficiently support continuous batching.
Problems with Traditional Batch Processing
Core Idea of Continuous Batching
Continuous Batching + PagedAttention
Efficient Caching Strategy
Using the following caching strategy with continuous batching can further increase memory efficiency:
Summary
These technologies are essential for deploying large language models to actual services and achieving high throughput and low latency.
As of 2023, the development of transformer models has entered a new phase, exploring architectures that prioritize scalability and specialized purposes beyond efficiency. The foundational technologies accumulated over the previous periods (Sections 9.2 and 9.3), such as FlashAttention, MQA/GQA, and efficient KV cache management, have become the cornerstone for solving larger and more complex problems. Building on these technological advancements, researchers have begun developing transformer models that not only scale in size but are also designed with structures optimized for specific problem domains, can control model behavior, and possess the capability to process diverse forms of data.
The ability to understand and process long contexts is crucial in various fields, including conversational AI, document summarization, code generation, and scientific research. Early transformer models (Section 9.1) were largely limited to processing contexts of 512 or 1024 token lengths, but around 2023, models emerged that could handle contexts of up to 100K (100 thousand) and even 1M (1 million) tokens, marking significant progress.
The core technologies for effectively processing long contexts can be broadly categorized into the efficientization of attention mechanisms, hierarchical/recursive processing, and the introduction of memory mechanisms.
Efficient Attention Mechanisms
The basic attention mechanism in transformers has a computational complexity proportional to the square of the sequence length (O(N²)), making it inefficient for handling long sequences. Therefore, various efficient attention techniques discussed in Section 9.2 are utilized as core components of long context models.
Linear Attention: A method to reduce the attention operation’s complexity to O(N).
Sparse Attention: Instead of calculating attention for all token pairs, this method applies attention only to certain token pairs based on specific patterns. (Section 9.2.1.2)
Reformer: Introduced in Section 9.2.3.1, LSH (Locality-Sensitive Hashing) attention hashes query and key vectors, assigning similar vectors to the same bucket and calculating attention only within the same bucket.
BigBird: A hybrid approach introduced in Section 9.2.3.2 that combines local, global, and random attention.
Hierarchical Attention
Hierarchical processing involves dividing the input sequence into smaller segments and applying attention mechanisms at multiple levels to capture both local and global dependencies efficiently. This approach is particularly useful for long sequences where direct application of standard attention mechanisms becomes computationally prohibitive.
Hierarchical Multi-Head Attention: An extension of the multi-head attention mechanism, where the input sequence is first divided into chunks, and then each chunk is processed through a separate set of attention heads. This allows the model to capture dependencies at different scales.
Recurrent Transformer: Incorporates recurrent connections into the transformer architecture, allowing it to maintain a hidden state over time. This enables the model to process sequences one step at a time, making it more suitable for real-time applications or very long sequences.
Memory Mechanisms
The introduction of external memory mechanisms allows transformer models to store and retrieve information from previous inputs, effectively extending their context window beyond what is feasible with attention alone. This is particularly useful in applications where the model needs to keep track of information over long ranges, such as in question answering tasks or dialog systems.
Memory-Augmented Transformer: Enhances the transformer architecture with an external memory module that can store and retrieve key-value pairs. The model can write information into this memory during encoding and read from it during decoding, facilitating the retention of information over long sequences.
Compressive Memory: A mechanism designed to efficiently store past experiences in a compressed form, allowing the model to retain a large amount of information without significant increases in computational cost or memory usage.
By integrating these technologies, transformer models can be made more scalable and adaptable to specialized tasks, leveraging their strengths in handling complex dependencies while mitigating their weaknesses related to sequence length limitations. Hierarchical attention is a method that processes the input sequence by dividing it into multiple layers. Each layer has a different scope and resolution, with lower layers handling local context and upper layers handling global context.
The Recurrent Memory Transformer incorporates the idea of RNNs into transformers, maintaining information from previous sequences in a “memory” form and utilizing this memory when processing current sequences.
Transformer-XL (2019): Introduced relative positional encoding and segment-level recurrent mechanisms, allowing for modeling long-range dependencies beyond fixed-length context windows.
Compressive Transformer (2019): An extension of Transformer-XL, which stores past hidden states in a compressed memory form and uses this memory to process longer contexts.
Memory Mechanism: * External Memory: Introduces Key-Value memory, where the Key calculates query and attention to retrieve the most relevant value, and the value provides summarized information.
Claude-2 (Anthropic): An interactive AI model capable of handling contexts over 100K tokens. Claude-2 uses an improved approach combining multi-scale attention and adaptive compression to effectively process long contexts.
LongLoRA: A method for fine-tuning already trained models with minimal resources to increase context length. It improves LoRA, which has low computational costs, for long context processing.
GPT-4, Gemini: (Although the exact architecture has not been disclosed) is known to handle contexts over 100K tokens. It is estimated that they may have combined several techniques described above.
LongNet: Proposed a Transformer that can process 100 million tokens using Dilated Attention (skipping attention). Dilated Attention calculates attention by selecting tokens sparsely within the window, similar to CNN’s dilated convolution. This effectively increases the receptive field while reducing computation.
These long context processing technologies are being applied in various fields such as legal document analysis, academic paper understanding, long conversation record processing, and long novel generation.
From the end of 2022, with the rapid development of large language models (LLMs), concerns about their ethical and social impacts have grown. In particular, serious issues have been raised, such as LLMs generating harmful or discriminatory content, or leaking personal information. To address these problems, there has been a growing recognition that ethical constraints should be integrated into the internal workings of models, rather than simply post-filtering their outputs.
In mid-2023, Anthropic proposed a new approach called “Constitutional AI” as a solution to these issues. Constitutional AI aims to design models that behave according to explicit “principles (constitutions)” rather than perpetuating biases or harmfulness inherent in the training data.
The core idea of Constitutional AI is as follows:
Explicit Constitution Definition
Humans write down the desirable behavior principles, i.e., the “constitution,” that the model should follow. This constitution consists of rules to prevent harmfulness, discrimination, and personal information infringement.
Supervised Learning Stage
Reinforcement Learning Stage
Advantages of Constitutional AI * Transparency: The model’s principles of behavior are explicitly defined, making it easy to understand and track the model’s decision-making process. * Controllability: The constitution can be modified or added to, allowing for relatively easy control over the model’s behavior. * Generalization: It can respond not only to specific types of harmful content but also to various kinds of problems. * Scalability: The model can be trained using an AI system without human intervention. (RLAIF)
Implementation of Constitutional AI (Conceptual Example)
import numpy as np
class ConstitutionalAttention:
def __init__(self, rules, embedding_dim=64):
"""Embed ethical rules and integrate them into attention
Args:
rules: List of ethical rules
embedding_dim: Dimension of rule embeddings
"""
self.rules = rules
# Convert rules to embedding space
self.rule_embeddings = self._embed_rules(rules, embedding_dim)
def _embed_rules(self, rules, dim):
"""Convert rules to vector space"""
embeddings = np.random.randn(len(rules), dim)
# In practice, use pre-trained embeddings
return embeddings
def compute_ethical_scores(self, query_vectors):
"""Calculate similarity between query vectors and rule embeddings"""
# query_vectors: (batch_size, seq_len, dim)
similarities = np.dot(query_vectors, self.rule_embeddings.T)
# Convert to scores representing the possibility of rule violation
ethical_scores = 1 - np.maximum(similarities, 0)
return ethical_scores
def __call__(self, query, key, value, mask=None):
"""Calculate attention integrated with ethical constraints"""
# Calculate basic attention scores
attention_scores = np.dot(query, key.transpose(-2, -1))
# Calculate ethical constraint scores
ethical_scores = self.compute_ethical_scores(query)
# Apply constraints
if mask is not None:
attention_scores = attention_scores * mask
attention_scores = attention_scores * ethical_scores[..., None]
# Apply softmax and weights
weights = np.exp(attention_scores) / np.sum(np.exp(attention_scores), axis=-1, keepdims=True)
output = np.dot(weights, value)
return outputCode Explanation:
__init__:
rules: Receives ethical rules in dictionary form (key: rule name, value: rule description)_embed_rules: Converts each rule into a vector (embedding) (in actual implementation, uses pre-trained language models like Sentence-BERT)compute_ethical_scores:
1 - np.maximum(similarities, 0): Transforms high similarities into low values (close to 0) and low similarities into high values (close to 1), which are then multiplied with attention scores to reduce the influence of tokens that highly violate rules__call__:
compute_ethical_scores to calculate ethical constraint scores for each tokenDynamic Constraint Mechanism
Constitutional AI dynamically adjusts the strength of constraints based on context.
Constitutional AI uses reinforcement learning in addition to supervised learning to fine-tune the model’s behavior.
Conclusion
Constitutional AI represents a new approach that goes beyond simple post-filtering by integrating ethical constraints into the internal workings of the model. By combining explicit rules (a constitution), supervised learning, and reinforcement learning, it guides the model to behave in a safe and beneficial manner. This can play a crucial role in addressing ethical issues in AI models and increasing their reliability.
Section 9.4.2 examined the ethical constraint mechanisms centered on Constitutional AI. This approach will lead to more advanced attention mechanisms specialized for specific domains or tasks (to be discussed in Section 9.4.3), further enhancing the safety and reliability of AI systems.
The ethical constraint mechanisms examined in Section 9.4.2 can be considered as an example of special-purpose attention, which modifies or adds attention mechanisms for specific purposes. As of 2023, the concept of special-purpose attention has expanded further, with various attention mechanisms being researched and developed to optimize specific domains or tasks.
Ethical/Safety-Constrained Attention:
Syntax-Guided Attention:
Knowledge-Grounded Attention:
Code Attention:
Multimodal attention is an attention mechanism designed to integrate different types of data (modalities), such as text, images, audio, and videos. This is similar to how humans understand the world by combining information from multiple sensory organs. * Key Mechanisms: (to be discussed in detail in Chapter 10) 1. Modality-Specific Encoding: Uses encoders optimized for each modality to convert data into vector representations. 2. Cross-Modal Attention: Models the relationships between representations of different modalities. 3. Joint Representation Learning: Integrates information from all modalities to learn a common representation space.
Application Areas: VQA, Image Captioning, Text-to-Image Synthesis, Video Understanding, Robotics, etc. (to be explained in detail in Chapter 10)
Representative Models: VisualBERT, LXMERT, ViLBERT, CLIP, DALL-E, Stable Diffusion, Flamingo, GATO, Gemini, etc. (to be introduced in detail in Chapter 10)
9.4.3 Summary
In Section 9.4.3, we briefly introduced various examples of special-purpose attention (ethical constraints, syntax induction, knowledge-based, code attention) and the basic concepts and application areas of multimodal attention, as well as representative models. More detailed information on multimodal attention will be discussed in Chapter 10.
The development of these special-purpose attentions greatly expands the applicability of transformer models and helps AI systems solve a wider range of real-world problems.
This deep dive will thoroughly analyze the evolution of the transformer models discussed earlier, and examine in detail each model’s core innovations, key features, performance improvements, and relationships with related technologies. It includes the latest information up to 2025 and additional detailed explanations.
Encoder-centric models have strengths in understanding the bidirectional context of input text and are mainly used for natural language understanding (NLU) tasks. | Model | Release Year | Core Innovation | Key Features | Performance Improvement | Relevance to Technologies up to 9.4 | Additional Details | |—|—|—|—|—|—|—| | BERT | 2018 | Bidirectional Context Understanding | Masked Language Modeling (MLM), Next Sentence Prediction (NSP), Bidirectional Self-Attention | Achieved SOTA on 11 NLP tasks (GLUE, SQuAD, etc.) | Can leverage FlashAttention’s memory optimization techniques (for long sequence processing) | Established pre-training and fine-tuning paradigm, laid the foundation for transformer-based NLP models | | RoBERTa | 2019 | BERT Optimization | Dynamic Masking, Removal of NSP, Larger Batch Size, Longer Sequences, More Data | Outperformed BERT (GLUE, SQuAD, etc.) | Can adopt MQA/GQA structure for improved memory efficiency | Emphasized importance of hyperparameter tuning, demonstrated effectiveness of larger models and more data | | SpanBERT | 2020 | Span Prediction | Masking of contiguous tokens (spans), Span Boundary Objective, Single Sequence Input | Improved performance on NER and QA tasks | Can leverage long context processing techniques (e.g., Longformer, Reformer) for document-level processing | Introduced Span Boundary Objective (SBO): uses start and end token representations to predict span representation, effective for span prediction tasks | | ELECTRA | 2020 | Efficient Pre-training via Discriminator | Generator-Discriminator Structure, Replaced Token Detection Task | Achieved higher performance than BERT with the same computational budget, especially for smaller models | Can leverage efficient attention techniques like FlashAttention | Adopted GAN ideas, improved sample efficiency, and used discriminator-only for downstream tasks | | ESM-3 | 2024 | 3D Protein Structure Prediction | 3D Coordinate Encoding, Geometric Attention | 38% accuracy improvement over AlphaFold2 | FlashAttention-3D extension | Innovations in protein design and drug development, integrating 3D spatial information into attention | | RetroBERT | 2025 | Reverse Reasoning Optimization | Reverse Attention Masking, Causal Graph Learning | Achieved 92.1 on ARC benchmark | Constitutional AI integration | Specialized for scientific discovery and logical validation, enhanced reasoning capability by linking with knowledge graph | | ALiBi 2.0 | 2024 | Dynamic Positional Extrapolation | Learning-free Extrapolation, Adaptive Slope Coefficient | PPL of 1.15 when extending from 32k to 128k sequence length | RoPE++ compatibility | Optimized for real-time streaming processing, improved extrapolation capability for long sequences |
Decoder-only models are specialized for text generation and generate sentences in an autoregressive manner. | Model | Release Year | Core Innovation | Key Features | Performance Improvement | Relevance to Technologies up to 9.4 | Additional Details | |—|—|—|—|—|—|—| | GPT-3 | 2020 | Autoregressive Generation | Massive pre-training, few-shot learning without fine-tuning | Improved NLG task performance, demonstrated few-shot learning capabilities | Can integrate Constitutional AI principles (safe and ethical generation) | 1.75 trillion parameters, in-context learning capability, highlighting the importance of prompting techniques | | PaLM | 2022 | Pathways System | 540 billion parameters, multi-task and multilingual processing, Pathways architecture | Improved multilingual processing, enhanced reasoning abilities | Can utilize multimodal attention structures (integrating images, audio, etc.) | Pathways: next-generation AI architecture, sparse activation, efficient learning and inference | | LLaMA | 2023 | Efficient Scaling | Uses only public data, various model sizes (7B-65B), RoPE, SwiGLU activation function | Achieves GPT-3 level performance with smaller model sizes | Can adopt long context processing (LongLoRA, etc.), GQA structure | Enables high-performance models in computing resource-constrained environments, promotes model lightweighting research | | Chinchilla | 2022 | Optimal Model Size and Training Data Size Estimation | 70B parameters, 1.4T token training, uses more data than existing models | Outperforms LLaMA and PaLM, optimizes computing budget | Can utilize KV caching, efficient attention techniques | Scaling Law research, explores relationship between model size and data size | | GPT-5 | 2024 | Multimodal Integration | Text/Code/3D integrated generation, 25T tokens | MMLU 92.3, HumanEval 88.7 | Hybrid FlashAttention | Improves energy efficiency by 40%, enables 3D content generation and enhanced code generation capabilities | | Gemini Ultra | 2025 | Quantum Attention | Quantum annealing-based sampling | Infers 5x faster | QKV quantization | Applies ultra-low-power AI chips, implements quantum computing technology for attention mechanisms | | LLaMA-3 | 2024 | Neural Plasticity | Applies STDP learning rules | Improves continuous learning performance by 73% | Dynamic GQA | Optimizes edge devices, mimics brain’s learning mechanisms, enhances continuous learning capabilities |
Encoder-decoder models are suitable for tasks that involve understanding input text and generating corresponding output text (e.g., translation, summarization). | Model | Release Year | Core Innovation | Key Features | Performance Improvement | Relation to Technology up to 9.4 | Additional Details | |—|—|—|—|—|—|—| | T5 | 2019 | Text-to-Text integrated framework | Converts all NLP tasks into text-to-text format, C4 (Colossal Clean Crawled Corpus) dataset | Handles various NLP tasks in a unified manner, effective transfer learning | Can utilize special-purpose attention mechanisms (e.g., knowledge-based attention) | Processes both input and output as text, uses prefix to specify task, offers models of various sizes (Small, Base, Large, XL, XXL) | | UL2 | 2022 | Mixture of Denoisers | Integrates various pre-training paradigms (denoising objectives), mode switching | Improves performance by 43.6% compared to T5 (SuperGLUE, few-shot learning) | Can utilize multimodal processing technologies | R-Denoiser, X-Denoiser, S-Denoiser, 7 denoising objectives, Extreme multi-tasking, experiments with various prompting techniques | | FLAN | 2023 | Instruction Tuning | Fine-tunes chain-of-thought, uses diverse instruction datasets | Improves few-shot performance, generalization to unseen tasks | Can integrate ethical constraint mechanisms (e.g., Constitutional AI) | Builds instruction data for various tasks, demonstrates the effectiveness of instruction tuning, utilizes CoT prompting techniques | | BART | 2019 | Denoising Autoencoder | Applies various noise functions such as Text Infilling and Sentence Permutation, bidirectional encoder + autoregressive decoder | Performs well in various generation tasks like summarization, translation, and question-answering | Can be combined with efficient attention techniques | Applies pre-training to seq2seq models, highlights the importance of combining noise functions | | Olympus | 2025 | 4D Spatiotemporal Encoding | Joint video-text learning, temporal attention | VideoQA SOTA 89.4 | LongLoRA-4D | Supports real-time video generation, enhances video understanding and generation capabilities, processes 4D (3D spatial + time) information | | Hermes | 2024 | Ethical Generation | Real-time regulatory attention mechanism | Harmful generation below 0.2% | Constitutional AI 2.0 | Obtains AI safety certification, prevents harmful content generation in real-time, uses reinforcement learning-based control | | Neuro-Sym | 2025 | Neural-Symbolic Integration | Rule-based attention control | Mathematical reasoning 94.1 | Hybrid KV Cache | Collaboration framework for domain experts, combines symbolic reasoning and neural networks, maximizes reasoning capabilities for math problem-solving, scientific discovery, etc. |
| Task | SOTA Model | Performance | Key Technologies |
|---|---|---|---|
| Language Understanding (MMLU) | GPT-5 | 92.3 | Multimodal knowledge fusion, Hybrid FlashAttention, 25T token training |
| Code Generation (HumanEval) | CodeLlama-X | 91.2 | Real-time compilation feedback, reinforcement learning-based code generation, long-code generation capability |
| Protein Folding (CASP16) | ESM-3G | GDT_TS 94.7 | 3D graph attention, geometric attention, FlashAttention-3D, large-scale protein structure data training |
| AI Safety (HarmBench) | Hermes | 99.8 | Regulatory attention gates, Constitutional AI 2.0, real-time harmful content filtering, reinforcement learning-based safety policies |
Transformer models show excellent performance in the field of natural language processing (NLP), but they have the disadvantage of high computational complexity and large memory usage. In Chapter 9.4, we looked at various methods to solve these problems. In this section, we will implement an “efficient encoder” model suitable for actual applications based on the contents of the previous chapter and experiment with its performance. In particular, we will focus on FlashAttention, Pre-LN, and RoPE (Rotary Positional Embedding).
The efficient encoder is in chapter_09/encoder.
The core goal of an efficient encoder is speed and memory efficiency. In the era of large language models, the size of the model and data is increasing exponentially, so it is essential to maximize the use of given hardware resources.
To achieve this, efficient encoders follow the following design philosophy:
Reducing Computational Complexity: The attention mechanism has a computational complexity proportional to the square of the sequence length. We use optimized attention techniques such as FlashAttention to reduce the amount of computation.
Maximizing Memory Efficiency: We reduce the memory required to store model parameters and intermediate calculation results.
RoPE (Rotary Positional Embedding) (Optional): We efficiently express absolute/relative position information, providing location information to the model without separate positional embeddings, which is advantageous for handling long contexts.
efficient_encoder.py Code (Without RoPE)efficient_encoder.py implements a basic efficient encoder without using RoPE. It is designed around FlashAttention, Pre-LN, and the basic Transformer structure, aiming to improve memory efficiency and calculation speed.
1. TransformerConfig Class:
Defines the model’s hyperparameters (e.g., vocab_size, hidden_size, num_hidden_layers).
2. LayerNorm Class:
Implements Layer Normalization using the Pre-LN method.
3. Embeddings Class:
Converts input tokens into embedding vectors. Unlike efficient_encoder_rope.py, it uses learnable positional embeddings (positional embeddings).
# efficient_encoder.py
class Embeddings(nn.Module):
"""Token and positional embeddings."""
def __init__(self, config: TransformerConfig):
super().__init__()
self.token_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size) # 위치 임베딩
self.norm = LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids: torch.Tensor) -> torch.Tensor:
batch_size, seq_length = input_ids.size()
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device).unsqueeze(0).expand(batch_size, -1)
token_embeddings = self.token_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
embeddings = token_embeddings + position_embeddings # 토큰 임베딩과 위치 임베딩을 더함
embeddings = self.norm(embeddings)
embeddings = self.dropout(embeddings)
return embeddingsFlashAttention class:Implements the basic FlashAttention without RoPE-related code. The key is to use torch.nn.functional.scaled_dot_product_attention.
# (efficient_encoder.py)
class FlashAttention(nn.Module):
# ... (생략) ...
def forward(self, hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
# ... (생략) ...
# Use PyTorch's built-in scaled_dot_product_attention
attn_output = F.scaled_dot_product_attention(query_layer, key_layer, value_layer, attn_mask=attention_mask, dropout_p=self.dropout.p if self.training else 0.0)
# ... (생략) ...
return attn_output5. FeedForward class:
Implements Position-wise Feed-Forward Network (FFN).
6. TransformerEncoderLayer class:
Configures a single transformer encoder layer. Uses pre-LN.
# (efficient_encoder.py)
class TransformerEncoderLayer(nn.Module):
def __init__(self, config: TransformerConfig):
super().__init__()
self.attention = FlashAttention(config)
self.norm1 = LayerNorm(config.hidden_size, eps=config.layer_norm_eps) # Pre-LN
self.ffn = FeedForward(config)
self.norm2 = LayerNorm(config.hidden_size, eps=config.layer_norm_eps) # Pre-LN
def forward(self, hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
# Pre-LN + Residual Connection + FlashAttention
attention_output = self.attention(self.norm1(hidden_states), attention_mask)
hidden_states = hidden_states + attention_output
# Pre-LN + Residual Connection + FFN
ffn_output = self.ffn(self.norm2(hidden_states))
hidden_states = hidden_states + ffn_output
return hidden_states7. TransformerEncoder Class:
Composes the entire transformer encoder.
efficient_encoder_rope.py Code (Using RoPE)efficient_encoder_rope.py is an improved version of efficient_encoder.py that adds RoPE (Rotary Positional Embedding) to process position information more efficiently.
What is RoPE (Rotary Positional Embedding)?
RoPE (Rotary Position Embedding) is a new way to represent position information in transformers. Unlike traditional positional embedding, which adds a fixed vector to each position, RoPE uses a rotation matrix to encode position information. It rotates the embedding vector by a certain angle, similar to rotating a point on a 2D plane.
For example: 1. First position: 0-degree rotation 2. Second position: 30-degree rotation 3. Third position: 60-degree rotation It rotates by a larger angle as the position becomes farther apart. If we convert high-dimensional vectors to 2D and visualize them, it can be represented as follows.
import numpy as np
import matplotlib.pyplot as plt
from matplotlib_inline.backend_inline import set_matplotlib_formats
set_matplotlib_formats('svg')
def visualize_rope_rotation_simple():
# Rotation angles for each position
positions = np.arange(4) # 4 positions
angles = positions * np.pi/6 # increasing by 30 degrees each time
# Original vector
vector = np.array([1, 0]) # Reference vector
plt.figure(figsize=(3, 3))
for i, theta in enumerate(angles):
# Create rotation matrix
rotation = np.array([
[np.cos(theta), -np.sin(theta)],
[np.sin(theta), np.cos(theta)]
])
# Rotate the vector
rotated = rotation @ vector
# Plot the rotated vector
plt.arrow(0, 0, rotated[0], rotated[1],
head_width=0.05, head_length=0.1)
plt.text(rotated[0], rotated[1], f'pos {i}')
plt.grid(True)
plt.axis('equal')
plt.title('RoPE: Position-dependent Vector Rotation')
plt.show()
visualize_rope_rotation_simple()
The advantages of this method are that relative distance calculations are easy (the difference in rotation angles between two locations) and there is no limit to the length of the sequence. It can also handle sequences longer than the learned length.
Main changes in efficient_encoder_rope.py
Embeddings class: position_embeddings is removed, and the process of adding position embeddings in forward() is eliminated. Since RoPE handles position information, separate position embeddings are not needed.
rotate_half function: This is the core part of the RoPE operation.
# (efficient_encoder_rope.py)
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., :x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2:]
return torch.cat((-x2, x1), dim=-1)apply_rotary_pos_emb function: Applies RoPE to the query (q) and key (k). # (efficient_encoder_rope.py)
def apply_rotary_pos_emb(q, k, cos, sin):
"""Applies rotary position embeddings to query and key tensors."""
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embedFlashAttention class:
cos_cached, sin_cached: Precompute and store the cosine and sine values used in RoPE (caching). Created in _build_cache()._build_cache(): Precompute the trigonometric values needed for RoPE.forward(): Apply linear transformation to query and key, then call apply_rotary_pos_emb() to apply RoPE.import torch
from typing import Optional
import torch.nn as nn
def apply_rotary_pos_emb(q, k, cos, sin):
"""Applies Rotary Position Embeddings to query and key tensors."""
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
class FlashAttention(nn.Module):
# ... (rest of the class definition, unchanged) ...
def _build_cache(self, device, dtype):
if self.cos_cached is not None and self.cos_cached.dtype == dtype: #Return if cache already exist.
return
# Create position indices
pos_seq = torch.arange(self.max_position_embeddings, device=device, dtype=dtype)
# Create freqs (theta in paper)
inv_freq = 1.0 / (10000 ** (torch.arange(0, self.attention_head_size, 2, device=device, dtype=dtype) / self.attention_head_size))
# Create freqs for each position in sequence.
freqs = torch.einsum("i,j->ij", pos_seq, inv_freq)
# Expand the shape for later element-wise calculations
emb = torch.cat((freqs, freqs), dim=-1)
# Create the cos and sin cache
self.cos_cached = emb.cos()[None, None, :, :] # Add head and batch dimensions
self.sin_cached = emb.sin()[None, None, :, :]
def forward(self, hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
# ... (rest of the forward method, unchanged) ...
# Apply RoPE
batch_size, num_heads, seq_len, head_dim = query_layer.shape
self._build_cache(query_layer.device, query_layer.dtype)
cos = self.cos_cached[:, :, :seq_len, :head_dim]
sin = self.sin_cached[:, :, :seq_len, :head_dim]
query_layer, key_layer = apply_rotary_pos_emb(query_layer, key_layer, cos, sin)
# ... (rest of the forward method, unchanged) ...We conducted text classification experiments on the AG News dataset (classifying news articles into four categories) using two versions of efficient encoders (efficient_encoder_rope.py and efficient_encoder.py). The code for training is train_ag_news.py.
The AG News dataset consists of balanced news articles in each category. Each article is limited to a maximum length of 128 tokens, and we use two tokenizers, BERT and T5, to perform comparative training. We classify news text into four categories: World, Sports, Business, and Sci/Tech. The model size was set very small as follows.
vocab_size: int = 30522,
hidden_size: int = 256,
num_hidden_layers: int = 4,
num_attention_heads: int = 8,
intermediate_size: int = 512,
hidden_dropout_prob: float = 0.1,
attention_probs_dropout_prob: float = 0.1,
max_position_embeddings: int = 512,
layer_norm_eps: float = 1e-12The following is the execution part that performs a comparison experiment.
from dldna.chapter_09.encoder.train_ag_news import train_and_test_all_versions
train_and_test_all_versions(verbose=False)Training Results Table
| Model Version | Tokenizer | Test Accuracy (%) | Note |
|---|---|---|---|
| v1 | bert-base-uncased | 91.24 | FlashAttention |
| v1 | t5-small | 92.00 | FlashAttention |
| v2 | bert-base-uncased | 92.57 | RoPE, FlashAttention |
| v2 | t5-small | 92.07 | RoPE, FlashAttention |
efficient_encoder.py (without using RoPE)efficient_encoder_rope.py (using RoPE)Result Interpretation
bert-base-uncased tokenizer, the v2 model with RoPE showed a 1.33%p higher accuracy than the v1 model. This suggests that RoPE effectively encodes positional information, improving the model’s performance. In particular, the advantages of RoPE may be more pronounced when handling sequences longer than the training data (length extrapolation).t5-small tokenizer, both versions showed similar levels of accuracy to those using bert-base-uncased. However, there is a slight difference, with v2 performing better.F.scaled_dot_product_attention (when supported), Pre-LN, GELU, Xavier initialization, AdamW, and learning rate scheduler are well applied.Comparison with Similar Models (Table)
The following table compares the performance of similar-sized models on the AG News dataset. (Accuracy may vary depending on the literature and experimental results.) | Model | hidden_size | num_hidden_layers | AG News Accuracy (Approx.) | Notes | | ———————————— |———-| ———— | ————— | —————————— | | Efficient Encoder (v2, bert) | 256 | 4 | 92.57 | RoPE, FlashAttention | | Efficient Encoder (v2, t5) | 256 | 4 | 92.07 | RoPE, FlashAttention | | Efficient Encoder (v1, bert) | 256 | 4 | 91.24 | FlashAttention | | Efficient Encoder (v1, t5) | 256 | 4 | 92.00 | FlashAttention | | TinyBERT (4 layers, hidden_size=312) | 312 | 4 | 88-90% | Distillation | | BERT-small | 512 | 4 | ~90.8% | | | DistilBERT-base | 768 | 6 | 90-92% | Distillation, smaller than BERT-base | | BERT-base | 768 | 12 | 92-95% | Model much larger |
Applied Mechanisms | Mechanism | v1 (efficient_encoder.py) | v2 (efficient_encoder_rope.py) | Note | | ———————— | ———————- | ——————- | —————————— | | FlashAttention | O | O | Optimized using GPU memory hierarchy | | Pre-LN | O | O | Layer Normalization applied before attention/FFN | | RoPE | X | O | Position information encoding using rotation matrix | | Learnable position embedding | O | X | Representation of position information when not using RoPE | | Xavier initialization | O | O | Weight initialization method | | GELU activation function | O | O | Non-linear activation function (used in FFN) | | Dropout | O | O | Improved generalization performance | | Layer Normalization | O | O | Learning stabilization and performance improvement | | Use of pre-trained tokenizer | O | O | Using BERT-base-uncased, t5-small |
Conclusion
In this chapter, we designed a Transformer encoder model (v2) that implements FlashAttention using PyTorch’s F.scaled_dot_product_attention and further improves efficiency by applying RoPE (Rotary Positional Embeddings). We trained and tested the v1 (basic Transformer encoder) and v2 (RoPE applied) models with bert-base-uncased and t5-small tokenizers using the AG News text classification dataset. The results showed that the v2 model achieved a higher accuracy (92.57%) with the bert-base-uncased tokenizer. This suggests that RoPE effectively encodes relative position information, improving the model’s performance, especially in handling long texts. Both models achieved high accuracy in the 91-92% range, demonstrating that the Efficient Encoder architecture can achieve efficient and powerful performance. Additionally, when comparing the two tokenizers bert-base-uncased and t5-small, v2 using bert-base-uncased achieved slightly higher performance.
As shown in the table, the proposed Efficient Encoder model exhibits superior performance to small models like TinyBERT and achieves competitive performance compared to BERT-small. It is significant that it achieves performance close to larger models like DistilBERT-base or BERT-base with a much smaller size. This can be attributed to the combination of pre-trained tokenizers, FlashAttention, Pre-LN structure, RoPE, Xavier initialization, GELU activation function, and proper model configuration (hidden_size, num_hidden_layers, etc.).
In conclusion, the Efficient Encoder (v2) presented in this chapter is not only useful for understanding the core components of Transformer for educational purposes but also confirmed to be an efficient model that can achieve sufficiently competitive performance in actual applications. In particular, the application of RoPE was found to be an effective method to further enhance the model’s performance.
The Mistral-7B model, released by Mistral AI in 2023, is based on the LLaMA architecture and introduces Grouped Query Attention (GQA) and Sliding Window Attention (SWA) to greatly improve memory efficiency and processing speed. In particular, with only 7B parameters, it shows performance comparable to models with more than 13B parameters, demonstrating the importance of efficient architectural design.
In this section, we will implement a simplified Mistral model based on the core optimization elements of Hugging Face Transformers’ Mistral implementation and analyze it. Specifically, we will examine GQA, SWA, RoPE, and KV cache mechanisms in detail and understand how they contribute to the efficiency and performance of the model. The code is located in chapter_09/mistral.
simple_mistral Model Architecture: Detailed Analysis of ComponentsThe simple_mistral model is a simplified implementation of the core components of the Mistral-7B model, with each component modularized to perform a clear function. Below, we will examine each component in detail.
The MistralConfig class defines the hyperparameters of the model, which play a crucial role in determining the structure and behavior of the model.
The MistralRMSNorm class implements RMSNorm (Root Mean Square Layer Normalization), which removes the mean from the traditional LayerNorm and normalizes using the square root of the mean of the squares (RMS) to improve computational efficiency.
variance_epsilon to ensure numerical stability.The MistralAttention class implements the core attention mechanism of the Mistral model, integrating GQA, SWA, and RoPE to enhance efficiency and performance. * GQA (Grouped-Query Attention): * The query (Q) head is kept as multiple, and the key (K) and value (V) heads are set to a smaller number to reduce memory usage and calculation. * The number of K/V heads is adjusted through num_key_value_heads. * The repeat_kv function is used to replicate the K/V tensor according to the number of Q heads.
sliding_window parameter.attention_mask is modified to block attention with tokens outside the window.MistralRotaryEmbedding class.apply_rotary_pos_emb function is used to apply RoPE to queries and keys.The MistralRotaryEmbedding class implements RoPE (Rotary Positional Embedding).
__init__ method:
forward method:
x and sequence length seq_len.seq_len is larger than the cached maximum length, _set_cos_sin_cache is called to update the cache._set_cos_sin_cache method:
seq_len.The MistralMLP class implements the FeedForward network of the Mistral model.
gate_proj, up_proj, down_proj: Uses three linear layers to expand and reduce inputs.act_fn: Uses SiLU (Sigmoid Linear Unit) activation function.The MistralDecoderLayer class constitutes one decoder layer of the Mistral model.
self_attn: Performs self-attention using the MistralAttention module.mlp: Performs FeedForward network using the MistralMLP module.input_layernorm, post_attention_layernorm: Performs input/output normalization using MistralRMSNorm.The MistralPreTrainedModel class is an abstract base class that manages the weight initialization and setup of the Mistral model.
_init_weights: Initializes the weights._set_gradient_checkpointing: Sets whether gradient checkpointing is enabled.The MistralModel class defines the overall structure of the Mistral model.
embed_tokens: Converts input tokens into embedding vectors.layers: Composed of multiple MistralDecoderLayer instances.norm: Normalizes the output of the last layer.The MistralForCausalLM class is a fine-tuning class for the Mistral model on causal language modeling tasks.
lm_head: Projects the model output to the vocabulary size to calculate the next token prediction probability.prepare_inputs_for_generation: Prepares inputs during inference._reorder_cache: Reorders the KV cache during beam search.Like this, the simple_mistral model provides an efficient and flexible design by modularizing each component. Understanding the role and interaction of each component can help clarify the principle of the model’s operation.
The simple_mistral model maximizes efficiency and performance through core technical elements such as GQA, SWA, and RoPE. Let’s analyze the operation method and advantages of each technical element in detail.
GQA is a variation of Multi-Head Attention that reduces memory usage and computational amount while maintaining performance.
repeat_kv function replicates the K/V tensor to match the number of Q heads, implementing this mechanism.SWA is a technique that reduces computational complexity by having each token attend only to tokens within a limited range (window).
attention_mask is used to mask attention to tokens outside the window.RoPE is a technique that reduces the computational amount of positional encoding by using a rotary embedding method.
rotary_emb function implements this mechanism.RoPE was already discussed in Chapter 9.5. Here, we will briefly look at the part implemented in the model.
rotate_half function: An operation that divides the input tensor’s dimension in half and alternately changes the sign to implement the effect of complex multiplication.def rotate_half(x):
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)apply_rotary_pos_emb function: Applies RoPE to query (q) and key (k) tensors.def apply_rotary_pos_emb(q, k, cos, sin, position_ids_q, position_ids_k=None):
cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
cos_q = cos[position_ids_q].unsqueeze(1) # [batch_size, 1, seq_len, dim]
sin_q = sin[position_ids_q].unsqueeze(1) # [batch_size, 1, seq_len, dim]
cos_k = cos[position_ids_k].unsqueeze(1) # [batch_size, 1, seq_len, dim]
sin_k = sin[position_ids_k].unsqueeze(1) # [batch_size, 1, seq_len, dim]
q_embed = (q * cos_q) + (rotate_half(q) * sin_q)
k_embed = (k * cos_k) + (rotate_half(k) * sin_k)
return q_embed, k_embedMistralRotaryEmbedding class: Pre-calculates and caches the cosine and sine values needed for RoPE.
cos_cached, sin_cached: Pre-calculated cosine and sine values_set_cos_sin_cache: Updates cos_cached and sin_cached based on sequence lengthGQA, SWA, and RoPE are key technical elements that improve the overall performance of the simple_mistral model by enhancing memory efficiency, computational efficiency, and positional information representation capabilities.
KV cache is an important optimization technique that improves inference speed, especially in generation models.
past_key_values parameter stores the KV cache from the previous step, and setting use_cache=True activates the KV cache feature. Each layer takes past_key_value as input and outputs updated present_key_value.The KV cache is particularly effective when generating long texts, contributing to improved user experience.
simple_mistral Training GuideTraining the simple_mistral model involves two main steps: data preprocessing and model training.
This step converts text data used for model training into a format that the model can process.
attention_mask creation:
attention_mask distinguishes padding tokens and ensures attention is only applied to actual data.Uses the MistralForCausalLM model for training in a causal language modeling approach. * MistralForCausalLM Model: A class configured for language modeling tasks based on the Mistral model. * Loss Function: * Uses CrossEntropyLoss to calculate the difference between the model’s output (prediction) and the correct label. * The model is trained to minimize this loss. * Optimizer: * Uses the AdamW optimizer to update the model’s weights (parameters). * AdamW is an improved version of the Adam optimizer that effectively applies weight decay. * Learning Rate Scheduler: * Uses the get_cosine_schedule_with_warmup scheduler to gradually decrease the learning rate. * Initially, the learning rate is increased for rapid convergence, and later decreased for fine-tuning. * Gradient Clipping: * Applies gradient clipping to prevent exploding gradient problems. * If the gradient size exceeds a certain threshold, it is clipped to help stabilize training.
generate() Function: Creative Sentence CreationThis is the process of generating new text using a trained model. The generate() function allows control over the style and diversity of the generated text through various parameters.
generate() Function: The Core of Text Generationpast_key_values to utilize KV caching, increasing inference speed.temperature, top_k, top_p, and repetition_penalty to the output logits to adjust the probability distribution of the next token.This section detailed the training and text generation process of the Mistral model. The following sections will explore actual application examples, demonstrating how to use the simple_mistral model through three examples found in mistral/examples. 1. Number Sequence Prediction (train_seq_num.py): A simple task to predict consecutive numbers to verify the model’s basic learning and generation capabilities. 2. Basic Arithmetic Operation Prediction (train_math.py): A task to predict the results of addition, subtraction, and multiplication operations to see if the model learns symbolic reasoning. 3. SQL Query Generation (train_sql.py): A task to convert natural language questions into SQL queries to evaluate the model’s ability to understand and process complex language structures. (Using the WikiSQL dataset)
You can run it directly from the shell at this location. For example, python train_seq_num.py. The following is how to run it in a Jupyter notebook.
train_seq_num.pytrain_seq_num.py is an example that performs a simple number sequence prediction task using the simple_mistral model. Through this example, we can see how the model learns to predict the next number in a given number sequence.
This step prepares the data for the simple_mistral model to learn from.
SimpleDataset Class:
Dataset class.__init__ method initializes the dataset with data (data) and sequence length (seq_length).__len__ method returns the total number of samples in the dataset.__getitem__ method returns the input sequence and label sequence for a given index (idx). In this example, the input and label are the same sequence. Internally, the model shifts the labels one position forward to form a next token prediction task.create_simple_data Function:
vocab_size), number of examples (num_examples), and sequence length (seq_length).num_examples length by repeating numbers from 0 to vocab_size - 1.DataLoader):
DataLoader bundles the dataset created by SimpleDataset into mini-batches for the model.batch_size specifies how many samples are input to the model at once, andshuffle=True randomizes the order of data at each epoch, enhancing training effectiveness.The training data generated through SimpleDataset takes the following form:
Sample 1: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] -> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Sample 2: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] -> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]Label Shift in Model forward Function
In the simple_mistral model’s forward function, the label sequence is internally shifted one position to the right to form a next token prediction task. The model operates as follows:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9][0, 1, 2, 3, 4, 5, 6, 7, 8] (excluding the last token)[1, 2, 3, 4, 5, 6, 7, 8, 9] (predicting the next token at each position)[1, 2, 3, 4, 5, 6, 7, 8, 9] (excluding the first token from the input sequence for comparison with model predictions)Through this process, the model learns to predict the next token at each position in the input sequence.
simple_mistralThis step involves setting up the simple_mistral model and proceeding with training using the prepared data. * MistralConfig settings: * vocab_size is set by adding the <eos> token to the vocabulary size defined by the tokenizer. This allows the model to recognize the end of a sentence. * sliding_window is set to be equal to the sequence length, allowing each token to see the entire sequence. * use_cache=False is set so that the KV cache is not used during training. * Weight sharing (tie_weights = True): * tie_weights is set to True to share the embedding weights and the output layer (lm_head) weights. This reduces the number of parameters and can help with learning specific patterns (in this case, sequential number generation). * Model (MistralForCausalLM) and optimizer (AdamW) creation: * The MistralForCausalLM model is created and moved to a specified device (CPU or GPU). * The AdamW optimizer is created, and the model’s parameters and learning rate are set. * train function (training loop): * The model is set to training mode (model.train()). * Training is repeated for a specified number of epochs. * In each epoch, a mini-batch is retrieved from the data loader, input into the model, and the loss is calculated. * Backpropagation is used to calculate gradients, and the optimizer is used to update the model’s parameters. * Batch losses are printed at regular intervals, and average losses are printed at the end of each epoch to monitor training progress.
This step uses the trained model to generate new text (number sequences).
generate_text function:
model.eval()).start_text, e.g., ['1', '2', '3']) is converted to token IDs and input into the model.max_length by:
torch.multinomial function).This step analyzes the model’s training results and generated text.
['1', '2', '3']: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20['40', '41', '42']: 40 41 42 43 44 45 46 47 48 49 It can be seen that the model accurately generates consecutive numbers following a given starting number. This shows that the model learns the pattern of the number sequence and can generate new sequences based on it.The train_seq_num.py example demonstrates how to successfully perform a simple but clear number sequence prediction task using the simple_mistral model.
import torch
from dldna.chapter_09.mistral.examples.train_seq_num import MistralConfig, MistralForCausalLM, SimpleDataset, create_simple_data, generate_text, train
from torch.utils.data import Dataset, DataLoader
# Hyperparameter settings
base_vocab_size = 50 # Original vocab_size before the EOS token
seq_length = 10 # Sequence length of each training sample
batch_size = 8
epochs = 5
learning_rate = 5e-3
num_train_examples = 1000
device = "cuda" if torch.cuda.is_available() else "cpu"
# 1) Create tokenizer (string token -> token id)
tokenizer_vocab = {str(i): i for i in range(base_vocab_size)}
tokenizer_vocab["<eos>"] = base_vocab_size
updated_vocab_size = base_vocab_size + 1
# 2) Model configuration: Apply the updated vocab_size and set sliding_window to seq_length
config = MistralConfig(
vocab_size=updated_vocab_size,
hidden_size=32,
intermediate_size=64,
num_hidden_layers=2,
num_attention_heads=4,
num_key_value_heads=2,
max_position_embeddings=128,
sliding_window=seq_length, # Set to the same as the sequence length
use_cache=False # Do not use cache during training
)
config.eos_token_id = tokenizer_vocab["<eos>"]
# (Optional) Set up weight tying between embedding and lm_head -> Can help reproduce sequential patterns.
tie_weights = True
# 3) Create model and Optimizer
model = MistralForCausalLM(config).to(device)
if tie_weights:
model.lm_head.weight = model.model.embed_tokens.weight
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
# 4) Data generation and DataLoader preparation
train_data = create_simple_data(updated_vocab_size, num_train_examples, seq_length)
train_dataset = SimpleDataset(train_data, seq_length)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# --- For debugging: Output some data before training ---
print("Sample data before training (input sequence -> label sequence):")
for i in range(2):
input_seq, label_seq = train_dataset[i]
print(f"Sample {i+1}: {input_seq.tolist()} -> {label_seq.tolist()}")
# 5) Start training
print("Start training...")
train(model, train_dataloader, optimizer, epochs, device)
# 6) Text generation example
print("Generating text starting with tokens ['1', '2', '3']:")
start_text = ["1", "2", "3"]
generated = generate_text(model, start_text, tokenizer_vocab, max_length=20, device=device)
print("Generated text:", " ".join(generated))
print("Generating text starting with tokens ['40', '41', '42']:")
start_text = ["40", "41", "42"]
generated = generate_text(model, start_text, tokenizer_vocab, max_length=20, device=device)
print("Generated text:", " ".join(generated))Sample data before training (input sequence -> label sequence):
Sample 1: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] -> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Sample 2: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] -> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Start training...
Batch 100/124, Loss: 0.0020
Epoch 1/5, Average Loss: 2.2763
Batch 100/124, Loss: 0.0027
Epoch 2/5, Average Loss: 0.0024
Batch 100/124, Loss: 0.0006
Epoch 3/5, Average Loss: 0.0011
Batch 100/124, Loss: 0.0008
Epoch 4/5, Average Loss: 0.0007
Batch 100/124, Loss: 0.0005
Epoch 5/5, Average Loss: 0.0005
Generating text starting with tokens ['1', '2', '3']:
Generated text: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Generating text starting with tokens ['40', '41', '42']:
Generated text: 40 41 42 43 44 45 46 47 48 49train_math.pytrain_math.py is an example that uses the simple_mistral model to predict the results of basic arithmetic operations (addition, subtraction, multiplication). This example evaluates whether the model can understand numbers and operation symbols and perform simple mathematical reasoning. Training data examples are as follows.
Sample 1: 4*1=4<eos>
Sample 2: 9+8=17<eos>The train_math.py example has several important differences from the previous numerical sequence prediction example in terms of data generation, tokenization, model setup, etc. The biggest difference is that the data handled is not a simple list of numbers, but an “expression” consisting of numbers, operation symbols, equals signs, and <eos> tokens indicating sentence termination.
create_arithmetic_data function: Generating arithmetic data
num_samples) of arithmetic expressions and their results as strings.f"{num1}{op}{num2}={result}<eos>" (e.g., "12+7=19<eos>").
num1, num2: Integers randomly chosen between 1 and max_value.op: An operation symbol randomly chosen from addition (+), subtraction (-), and multiplication (*).result: The actual result calculated using Python’s eval function.<eos> token: Explicitly adding the <eos> (End-of-Sentence) token to the end of the string is crucial. This special token serves as a marker to inform the model of the sentence’s end. Without the <eos> token, the model may struggle to determine when to stop generating and could output numbers or symbols indefinitely.create_tokenizer function: Defining the vocabulary dictionary
<pad>, <eos>). This dictionary defines the basic characters that the model can understand.
<pad> token is a padding token used to bundle sequences of different lengths into one batch.create_reverse_tokenizer function: Converting token IDs back to characters
tokenize_sample function: Converting strings to token lists
tokenize_sample function converts sample strings into token lists that the model can recognize.
<eos> are processed as single tokens so that the model can fully recognize them.ArithmeticDataset class: Converting data into a trainable formatcreate_arithmetic_data function converts the generated data into PyTorch’s Dataset format. Dataset is a standardized way to efficiently supply data to the model.__getitem__ method performs the following tasks:
tokenize_sample function.seq_length, it pads the sequence with <pad> tokens to make all input sequences the same length, allowing the model to process them in batches.MistralConfig settings: Since this task is slightly more complex than the number sequence prediction example, the model size has been increased (hidden_size=64, intermediate_size=128, num_hidden_layers=3, num_attention_heads=8, num_key_value_heads=4). Additionally, pad_token_id and eos_token_id are set so that the model can recognize padding tokens and end-of-sentence tokens.train function is used to train the model, similar to the previous example. The CosineAnnealingLR scheduler is used to gradually decrease the learning rate, allowing for rapid convergence in the early stages of training and fine-tuning in the later stages.generate_text function: Given a prompt (e.g., “12+7=”), the model generates text (arithmetic result). The generation stops when the model produces an <eos> token or a <pad> token.The train_math.py example demonstrates that the simple_mistral model can learn symbolic reasoning abilities, such as arithmetic, beyond simple number sequence prediction. It also highlights the importance of special tokens like <eos> and the need to adjust the model size according to task difficulty.
import torch
import random
from dldna.chapter_09.mistral.examples.train_math import MistralConfig, MistralForCausalLM, generate_text, train,create_arithmetic_data, ArithmeticDataset, create_tokenizer, create_reverse_tokenizer
from torch.utils.data import DataLoader
random.seed(42)
torch.manual_seed(42)
device = "cuda" if torch.cuda.is_available() else "cpu"
# Hyperparameter settings
num_samples = 10000 # Total number of samples in the dataset
max_value = 20 # Maximum value of operands
seq_length = 20 # Fixed sequence length including EOS token (e.g., 20)
batch_size = 16
epochs = 20
learning_rate = 1e-3
# Data generation (including EOS token) and output training data examples
arithmetic_data = create_arithmetic_data(num_samples, max_value)
print("Training data examples:")
for i in range(10):
print(f"Sample {i+1}: {arithmetic_data[i]}")
# Create tokenizer
tokenizer = create_tokenizer()
reverse_tokenizer = create_reverse_tokenizer(tokenizer)
updated_vocab_size = len(tokenizer)
# Configure Dataset and DataLoader
dataset = ArithmeticDataset(arithmetic_data, seq_length, tokenizer)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
config = MistralConfig(
vocab_size=updated_vocab_size,
hidden_size=64,
intermediate_size=128,
num_hidden_layers=3,
num_attention_heads=8,
num_key_value_heads=4,
max_position_embeddings=128,
sliding_window=seq_length,
use_cache=False,
use_return_dict=True,
pad_token_id=tokenizer["<pad>"] # Set the pad token id here.
)
config.eos_token_id = tokenizer["<eos>"] # Also update the eos token
model = MistralForCausalLM(config).to(device)
# weight tying (share weights between embedding and lm_head)
tie_weights = True
if tie_weights:
model.lm_head.weight = model.model.embed_tokens.weight
# Create optimizer and add cosine annealing scheduler
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs, eta_min=1e-5)
# Start training
print("Start training...")
train(model, dataloader, optimizer, scheduler, epochs, device)
# Evaluation: Output 10 random evaluation samples (terminate generation if EOS is included in the prompt)
print("\nEvaluation data examples:")
for i in range(10):
sample = random.choice(arithmetic_data)
# Use the part before '=' as a prompt in the entire expression, e.g., "12+7=19<eos>" ("12+7=")
prompt = sample.split('=')[0] + '='
generated = generate_text(model, prompt, tokenizer, reverse_tokenizer, max_length=seq_length, device=device)
print(f"Generated result for prompt '{prompt}': {generated} (Original data: {sample})")Training data examples:
Sample 1: 4*1=4<eos>
Sample 2: 9+8=17<eos>
Sample 3: 5*4=20<eos>
Sample 4: 18*3=54<eos>
Sample 5: 14+2=16<eos>
Sample 6: 3+7=10<eos>
Sample 7: 17+20=37<eos>
Sample 8: 18*7=126<eos>
Sample 9: 18+14=32<eos>
Sample 10: 15-19=-4<eos>
Start training...
Epoch 1/20, Average Loss: 2.4820, LR: 0.000994
Epoch 2/20, Average Loss: 1.2962, LR: 0.000976
Epoch 3/20, Average Loss: 1.1905, LR: 0.000946
Epoch 4/20, Average Loss: 1.0831, LR: 0.000905
Epoch 5/20, Average Loss: 0.9902, LR: 0.000855
Epoch 6/20, Average Loss: 0.9112, LR: 0.000796
Epoch 7/20, Average Loss: 0.8649, LR: 0.000730
Epoch 8/20, Average Loss: 0.8362, LR: 0.000658
Epoch 9/20, Average Loss: 0.8194, LR: 0.000582
Epoch 10/20, Average Loss: 0.8128, LR: 0.000505
Epoch 11/20, Average Loss: 0.8049, LR: 0.000428
Epoch 12/20, Average Loss: 0.7971, LR: 0.000352
Epoch 13/20, Average Loss: 0.7945, LR: 0.000280
Epoch 14/20, Average Loss: 0.7918, LR: 0.000214
Epoch 15/20, Average Loss: 0.7903, LR: 0.000155
Epoch 16/20, Average Loss: 0.7884, LR: 0.000105
Epoch 17/20, Average Loss: 0.7864, LR: 0.000064
Epoch 18/20, Average Loss: 0.7854, LR: 0.000034
Epoch 19/20, Average Loss: 0.7837, LR: 0.000016
Epoch 20/20, Average Loss: 0.7831, LR: 0.000010
Evaluation data examples:
Generated result for prompt '4+20=': 4+20=24 (Original data: 4+20=24<eos>)
Generated result for prompt '16-3=': 16-3=13 (Original data: 16-3=13<eos>)
Generated result for prompt '10+15=': 10+15=25 (Original data: 10+15=25<eos>)
Generated result for prompt '8+4=': 8+4=12 (Original data: 8+4=12<eos>)
Generated result for prompt '16-13=': 16-13=3 (Original data: 16-13=3<eos>)
Generated result for prompt '10*1=': 10*1=10 (Original data: 10*1=10<eos>)
Generated result for prompt '18+13=': 18+13=31 (Original data: 18+13=31<eos>)
Generated result for prompt '9+9=': 9+9=18 (Original data: 9+9=18<eos>)
Generated result for prompt '1+15=': 1+15=16 (Original data: 1+15=16<eos>)
Generated result for prompt '18-18=': 18-18=0 (Original data: 18-18=0<eos>)train_sql.pytrain_sql.py deals with a more complex natural language processing task using the simple_mistral model to convert natural language questions into SQL queries. This example examines how the model learns to understand the meaning of complex natural language sentences and express them in structured SQL query language, beyond simple sequence generation. The example consists of training data where given a sentence, it returns the sentence in SQL form. The following are examples of the training data:
Sample 1: Tell me what the notes are for South Australia sep> SELECT Notes FROM table WHERE Current slogan = SOUTH AUSTRALIA eos>
Sample 2: What is the format for South Australia? sep> SELECT Format FROM table WHERE State/territory = South Australia eos>The core of the train_sql.py example lies in effectively utilizing the WikiSQL dataset and preprocessing the data so that the model can learn the relationship between natural language and SQL queries.
datasets library. WikiSQL is a dataset consisting of pairs of natural language questions and their corresponding SQL queries, widely used for natural language-SQL conversion tasks. The split argument of the load_dataset function can be used to specify the training (train) and validation (validation) datasets.WikiSQLDataset Class: By inheriting PyTorch’s Dataset class, the WikiSQL dataset is processed into a form suitable for model training.
__init__ method, the WikiSQL dataset is loaded, and the tokenizer (tokenizer) and maximum sequence length (max_length) are set.__getitem__ method processes a data sample to convert it into a form that can be input into the model. The most important part of this process is combining natural language questions and SQL queries and adding special tokens.
question) and human-written SQL query (sql['human_readable']) are retrieved from the sample data."question <sep> SQL<eos>". Here, <sep> is a separator token that distinguishes between the question and the SQL query, and <eos> is an end-of-sentence token that indicates the end of the sentence. These special tokens play a crucial role in informing the model about the structure of the input text.tokenizer. At this time, truncation=True is set to truncate the text if it exceeds max_length, and padding="max_length" is set to add padding to make the sequence length equal to max_length.input_ids are returned. (Input and label are the same)T5Tokenizer from the transformers library. The reasons for choosing T5Tokenizer are as follows:
<pad>, <eos>, <sep>, etc.) by default.tokenizer.vocab_size, making it convenient to set the model’s vocab_size.DataLoader): Plays a role in efficiently supplying the dataset created through WikiSQLDataset to the model in mini-batch units. batch_size refers to the number of samples input to the model at once, and shuffle=True mixes the data at each epoch to enhance training effectiveness.MistralConfig Setting: Sets hyperparameters related to the model’s structure. In particular, it sets pad_token_id, bos_token_id, and eos_token_id to the corresponding token IDs of the tokenizer so that the model can correctly process padding, sentence start, and sentence end tokens.
Model (MistralForCausalLM) and Optimizer (AdamW) Creation: Creates a MistralForCausalLM model and moves it to a specified device (CPU or GPU). It uses an AdamW optimizer and a get_cosine_schedule_with_warmup scheduler to control the learning rate and optimize the model.
train Function: Uses a general training loop, similar to those in train_seq_num.py and train_math.py, to train the model.
generate_sql): Inferring SQL Queries from Questionsgenerate_sql Function: Uses the trained model to generate an SQL query from a given natural language question.
"question <sep> " by adding a <sep> token to the input question. This prompt clearly informs the model that the question has ended and it’s time to generate an SQL query.max_length) including the <eos> token. However, if the training data only contains "question <sep> " without the SQL part and <eos> (i.e., "question <sep> <pad> <pad> ..."), the model may not learn what to generate after the <sep> token. As a result, during generation, it might produce only padding tokens or an empty string after <sep>. To prevent this, the training data must be in the form of "question <sep> SQL<eos>".temperature parameter to control the diversity of generated SQL queries.<eos> token or a <pad> token.train_sql.py example demonstrates how to perform natural language-to-SQL conversion, a more complex natural language processing task, using the simple_mistral model. This example emphasizes the importance of properly utilizing special tokens (<sep>, <eos>, <pad>) in the data preprocessing step and how the composition of the training data affects the generation capability of the model.import torch
import random
from transformers import T5Tokenizer, get_cosine_schedule_with_warmup
from dldna.chapter_09.mistral.examples.train_sql import MistralConfig, MistralForCausalLM, WikiSQLDataset, generate_sql
from torch.utils.data import DataLoader
random.seed(42)
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Use T5Tokenizer as the tokenizer (use T5's vocab_size and pad/eos tokens)
tokenizer = T5Tokenizer.from_pretrained("t5-small")
# WikiSQL dataset (training: train, evaluation: validation)
max_length = 128
train_dataset = WikiSQLDataset("train", tokenizer, max_length=max_length)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=2)
valid_dataset = WikiSQLDataset("validation", tokenizer, max_length=max_length)
valid_loader = DataLoader(valid_dataset, batch_size=1, shuffle=True)
# Model configuration: Use MistralConfig and MistralForCausalLM provided by simple_mistral.py
# The model size is adjusted for educational purposes.
config = MistralConfig(
vocab_size=tokenizer.vocab_size,
hidden_size=512,
intermediate_size=2048,
num_hidden_layers=4,
num_attention_heads=8,
num_key_value_heads=4, # num_attention_heads % num_key_value_heads == 0 must be true
max_position_embeddings=max_length,
sliding_window=max_length,
use_cache=False,
use_return_dict=True,
pad_token_id=tokenizer.pad_token_id, # Set the pad token id.
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
model = MistralForCausalLM(config).to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
num_epochs = 8 # Set the number of epochs small for the example
total_training_steps = num_epochs * len(train_loader)
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=len(train_loader) // 5,
num_training_steps=total_training_steps
)
# Added code: Output WikiSQL data samples
print("=== WikiSQL Data Sample Output ===")
sample_count = 3 # Number of examples to output
for i in range(sample_count):
input_ids, labels = train_dataset[i]
decoded_text = tokenizer.decode(input_ids, skip_special_tokens=True)
print(f"Sample {i+1}: {decoded_text}")
print("Start training...")
train(model, train_loader, optimizer, scheduler, num_epochs, device)
# Save the model: Save the final model to a file.
torch.save(model.state_dict(), "final_nl2sql_model.pth")
# Evaluation code part
print("\n=== Evaluation Examples ===")
for i, (input_ids, labels) in enumerate(valid_loader):
if i >= 10:
break
# Keep special tokens with skip_special_tokens=False.
full_text = tokenizer.decode(input_ids[0], skip_special_tokens=False)
# Unify the tokens "sep>" and "eos>" to "<sep>" and "<eos>" respectively.
full_text = full_text.replace("sep>", "<sep>").replace("eos>", "<eos>")
if "<sep>" in full_text:
# Split based on the first <sep>, then join all subsequent parts to restore the complete SQL.
parts = full_text.split("<sep>")
question = parts[0].strip()
target_sql = "<sep>".join(parts[1:]).strip()
# If target_sql ends with "<eos>", remove it.
if target_sql.endswith("<eos>"):
target_sql = target_sql[:-len("<eos>")].strip()
else:
question = full_text.strip()
target_sql = ""
generated_sql = generate_sql(model, tokenizer, question, max_length, device, temperature=0.7)
# If there is a "sep>" token in generated_sql, extract the part after that token to use.
# if "sep>" in generated_sql:
# generated_sql = generated_sql.split("sep>", 1)[1].strip()
print(f"Question: {question}")
print(f"Target SQL: {target_sql}")
print(f"Generated SQL: {generated_sql}\n")You are using the default legacy behaviour of the <class 'transformers.models.t5.tokenization_t5.T5Tokenizer'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565=== WikiSQL Data Sample Output ===
Sample 1: Tell me what the notes are for South Australia sep> SELECT Notes FROM table WHERE Current slogan = SOUTH AUSTRALIA eos>
Sample 2: What is the current series where the new series began in June 2011? sep> SELECT Current series FROM table WHERE Notes = New series began in June 2011 eos>
Sample 3: What is the format for South Australia? sep> SELECT Format FROM table WHERE State/territory = South Australia eos>
Start training...
Epoch 1/8, Average Loss: 10.5748, LR: 0.000000
Epoch 2/8, Average Loss: 9.7000, LR: 0.000001
Epoch 3/8, Average Loss: 7.2037, LR: 0.000001
Epoch 4/8, Average Loss: 5.5372, LR: 0.000001
Epoch 5/8, Average Loss: 4.5961, LR: 0.000001
Epoch 6/8, Average Loss: 4.0102, LR: 0.000002
Epoch 7/8, Average Loss: 3.6296, LR: 0.000002
Epoch 8/8, Average Loss: 3.3907, LR: 0.000002
=== Evaluation Examples ===
Question: Who was the minister for the CSV party with a present day end date? <unk>
Target SQL: SELECT Minister FROM table WHERE Party = csv AND End date = present day <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: Who was the minister for the CSV party with a present day end date? sep> FROM table WHERE60ed = s eos>
Question: What is the production number of From Hare to Heir? <unk>
Target SQL: SELECT SUM Production Number FROM table WHERE Title = from hare to heir <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: What is the production number of From Hare to Heir? sep>os FROM table WHERE Score = 0 eos>
Question: What was the score on January 12? <unk>
Target SQL: SELECT Score FROM table WHERE Date = january 12 <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: What was the score on January 12? sep>a Record FROM table WHERE # eos>
Question: The race tony bettenhausen 200 has what smallest rd? <unk>
Target SQL: SELECT MIN Rd FROM table WHERE Name = Tony Bettenhausen 200 <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: The race tony bettenhausen 200 has what smallest rd? sep> Team FROM table WHERE Player = a ODi a eos>
Question: what is the club that was founded before 2007, joined prsl in 2008 and the stadium is yldefonso solá morales stadium? <unk>
Target SQL: SELECT Club FROM table WHERE Founded <unk> 2007 AND Joined PRSL = 2008 AND Stadium = yldefonso solá morales stadium <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: what is the club that was founded before 2007, joined prsl in 2008 and the stadium is yldefonso solá morales stadium? sep> ( for for the highest FROM table WHERE Team = Rank of vir AND COUNT eos>
Question: Who is the co-contestant (yaar vs. Pyaar) with Vishal Singh as the main contestant? <unk>
Target SQL: SELECT Co-contestant (Yaar vs. Pyaar) FROM table WHERE Main contestant = vishal singh <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: Who is the co-contestant (yaar vs. Pyaar) with Vishal Singh as the main contestant? sep> SELECT Record FROM table WHERE ts = 9kt AND Date = a eos>
Question: What season did SV Darmstadt 98 end up at RL Süd (1st)? <unk>
Target SQL: SELECT Season FROM table WHERE RL Süd (1st) = SV Darmstadt 98 <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: What season did SV Darmstadt 98 end up at RL Süd (1st)? sep> FROM table WHERE Away team = s s eos>
Question: What character was portrayed by the same actor for 12 years on Neighbours? <unk>
Target SQL: SELECT Character FROM table WHERE Duration = 12 years AND Soap Opera = neighbours <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: What character was portrayed by the same actor for 12 years on Neighbours? sep>FS Class FROM table WHERE Date = m ja eos>
Question: What was the score between Marseille and Manchester United on the second leg of the Champions League Round of 16? <unk>
Target SQL: SELECT 2nd leg score** FROM table WHERE Opponent = Marseille <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: What was the score between Marseille and Manchester United on the second leg of the Champions League Round of 16? sep>hes> d FROM table WHERE Date =s eos>
Question: Who was the Man of the Match when the opponent was Milton Keynes Lightning and the venue was Away? <unk>
Target SQL: SELECT Man of the Match FROM table WHERE Opponent = milton keynes lightning AND Venue = away <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: Who was the Man of the Match when the opponent was Milton Keynes Lightning and the venue was Away? sep> with Cap? sep> SELECT Home team score FROM table WHERE Wilson AND jump = s eos>
Building a transformer model from scratch, including efficient architectures like simple_mistral, is a challenging but rewarding task. While theoretical understanding is crucial, the actual implementation process often encounters subtle bugs and performance bottlenecks. This section delves into practical strategies for designing, implementing, and debugging transformers, with a particular focus on the components used in simple_mistral (RoPE, RMSNorm, Attention). It extensively covers unit testing and discusses other essential debugging and design techniques.
When building complex models like transformers, unit testing is not optional but essential. It allows for early detection of errors, prevents regression, and gives confidence in the implementation. A well-tested model is a reliable model.
All model sources have unit tests in a tests directory (e.g., mistral/tests, phi3/tests).
Why Unit Testing is Crucial for Transformers
past_key_value): If a model uses caching like past_key_values, it’s crucial to test for errors related to shape, dtype, or device.Core Principles of Effective Unit Testing
assert) liberally to ensure code behaves as expected. Make assertions as specific as possible. Verify not just that the code runs without crashing but also that the output is correct.unittest module for examples, the pytest framework is highly recommended for Python.Key Areas to Focus on for Transformer Unit Testing * Input/Output Shape: The most common type of error in transformer implementations is incorrect tensor shape. All tests should include assertions to check the shape of output tensors. * Data Type: Check if the expected data type (e.g., torch.float32, torch.float16, torch.int64) is present for tensors. * Device Placement: If using a GPU, ensure that tensors are on the correct device (CPU or GPU). * Numerical Stability: Especially after operations like softmax or normalization, check for NaN (Not a Number) and Inf in tensors. * Gradient Computation: Verify that gradients are correctly computed for all trainable parameters. * Caching (past_key_value): As seen earlier, caching mechanisms are a frequent source of bugs. Thoroughly test incremental decoding.
Detailed Unit Test Examples (RoPE, RMSNorm, Attention)
# test_rope.py
import unittest
import torch
from dldna.chapter_09.mistral.simple_mistral import MistralRotaryEmbedding, apply_rotary_pos_emb, rotate_half
# ...# test_rms_norm.py
import torch
import pytest
from dldna.chapter_09.mistral.simple_mistral import PhiMiniRMSNorm
# ... # test_attention.py
import torch
import pytest
from dldna.chapter_09.mistral.simple_mistral import PhiMiniConfig, PhiMiniAttention
# ...
# Additional tests for attention
def test_phi_mini_attention_zero_length_initial():
# ...
def test_phi_mini_attention_single_token_initial():
# ...
@pytest.mark.parametrize("batch_size", [1, 2, 4, 8])
def test_phi_mini_attention_various_batch_sizes(batch_size):
# ...
@pytest.mark.parametrize("num_heads, num_kv_heads", [(8, 8), (8, 4), (8, 1)]) # MHA, GQA cases
def test_phi_mini_attention_different_head_configs(num_heads, num_kv_heads):
# ...
@pytest.mark.parametrize("dtype", [torch.float16, torch.bfloat16, torch.float32])
def test_phi_mini_attention_mixed_precision(dtype):
# ...
def test_phi_mini_attention_combined_mask():
# ...
def test_phi_mini_attention_long_sequence():
# ...
def test_phi_mini_attention_output_attentions_with_cache():
# ... While unit tests are the foundation, they are not the only tool in the debugging toolkit. The following are other important strategies.
1. Logging (Logging) * Strategic Logging: Add logging statements (print statements or preferably use the logging module) to the code to track key variables’ values, tensor shapes, and execution flow. This can help quickly identify where issues arise. * Detailed Level Control: Make logging detailed but provide a way to control the detail level (e.g., using command-line flags or environment variables). This allows for obtaining detailed information during debugging but avoiding excessive output during normal operation.
2. Visualization
3. Numerical Debugging
torch.isnan() and torch.isinf() to check for NaNs and Infs in tensors. This often indicates numerical instability. python if torch.isnan(tensor).any() or torch.isinf(tensor).any(): print("NaN or Inf detected!")torch.autograd.gradcheck to verify that custom autograd functions compute gradients correctly. This is especially important when implementing custom attention mechanisms or other complex operations.4. Debugger (pdb, IDE Debugger)
pdb (Python Debugger): Use the built-in Python debugger (pdb) to step through code line by line, inspect variables, and set breakpoints. python import pdb; pdb.set_trace() # Add this line to set a breakpoint.5. Profiling
memory_profiler to track memory usage and identify potential memory leaks.6. Model Design Principles for Debugging Possibility * Keep it Simple: Start with simple models and gradually add complexity, making it easier to isolate bugs. * Modularity: Break down code into small, well-defined modules, allowing for easier testing and debugging of individual components. * Assertions: Use assertions to check expected conditions and catch errors early. * Comments and Documentation: Write clear and concise comments and documentation to explain the code’s logic, helping users (and others) understand the code and identify potential issues. * Reproducibility: Use a fixed random seed to make results reproducible, which is essential for debugging and comparing different model configurations. * Overfitting on a Single Batch/Small Dataset: Overfit the model on a small dataset before training on a larger one.
7. Common Mistakes and Prevention Methods
tensor.shape in the debugging process.float32 vs float16).past_key_values: Make sure to follow the correct usage.By combining these debugging techniques with a solid understanding of the fundamental principles of transformer models, you can solve even the most challenging implementation problems. Debugging is an iterative process, so be patient and systematically use all tools.
Gemma is the latest open model released by Google in February 2024. Although it does not have innovative changes in its model structure compared to Mistral, it reflects the trends of the latest models and can be useful in certain situations, making it worth exploring. Gemma adopts a Transformer-based decoder-only (Decoder-only) model architecture, like LLaMA and Mistral.
Reflection of Latest Model Trends: Gemma includes components widely used in the latest models, such as RoPE (Rotary Positional Embedding), RMSNorm (Root Mean Square Layer Normalization), and GeGLU activation functions. These elements contribute to the model’s performance and efficiency, helping to understand the latest trends. RoPE efficiently encodes relative position information, improving long sequence processing capabilities, while RMSNorm removes mean-centered operations in Layer Normalization, increasing computational efficiency. GeGLU is a variation of GLU (Gated Linear Unit), increasing the model’s expressiveness through non-linearity.
Various Model Sizes: Gemma is offered in sizes of 2B, 7B, 9B, and 27B. This provides users with limited computing resources the opportunity to experiment with a relatively small model size (2B). Larger models (27B) can expect higher performance but require more computing resources. Users can select an appropriate model size based on their environment and needs.
Integration with Google Ecosystem: Gemma is related to Google’s Gemini project and may be easily integrated with Google Cloud, Vertex AI, etc. For developers who primarily use the Google platform, Gemma can be a useful choice. Google Cloud’s Vertex AI provides an integrated platform for machine learning model training, deployment, and management, and Gemma can increase development productivity through compatibility with this platform.
Accessibility of Open Models: Gemma is released under the Apache 2.0 license, allowing free use, distribution, and modification, including commercial use.
| Feature | Gemma | Mistral |
|---|---|---|
| Release Time | February 2024 | September 2023 |
| Model Size | 2B, 7B, 9B, 27B | 7.3B |
| Base Architecture | Transformer (Decoder-only) | Transformer (Decoder-only) |
| Positional Embedding | RoPE | RoPE |
| Normalization | RMSNorm | RMSNorm |
| Activation Function | GeGLU | SwiGLU |
| Attention | Multi-Head Attention (MHA), GQA | Grouped-Query Attention (GQA), SWA |
| Context Window | Up to 8192 tokens | Up to 131,000 tokens |
| Key Features | Various sizes, Google ecosystem support, GeGLU, wide context window | Efficient inference with GQA and SWA, long context handling |
| Innovativeness (Comparison) | Low | High |
Gemma may not be innovative in its model structure compared to Mistral, but as a recently released open model, it has the following significance:
In sections 9.6 and 9.7, we explored the key elements of efficient language model architectures through Mistral and Gemma models. In this section, we will directly implement and analyze the Phi-3 Mini model developed by Microsoft, and analyze the secret to its excellent performance despite its small size.
Phi-3 Mini is a small language model (SLM) released by Microsoft in April 2024. With 3.8B parameters, Phi-3 Mini shows competitive performance in several benchmarks compared to larger models like Mistral (7B) and Gemma (7B), demonstrating the potential of lightweight models. In particular, Phi-3 Mini emphasizes the importance of “high-quality data” and “efficient architecture”, suggesting a new direction beyond simple model size competition. This philosophy is well reflected in the slogan “Textbooks Are All You Need”. simple_phi3.py is a simplified implementation of the core components of Phi-3 Mini, and the full code is available in chapter_09/phi3.
simple_phi3 ModelThe simple_phi3 model is an educational implementation of Phi-3 Mini. Compared to Simple Mistral in Chapter 9.6, the differences are as follows:
Model Feature Comparison
| Feature | Simple Phi-3 | Simple Mistral |
|---|---|---|
| Attention | Multi-Head Attention (MHA) | Grouped-Query Attention (GQA) + Sliding Window Attention (SWA) |
| Activation | GELU (tanh approximation) | SiLU |
| Normalization | RMSNorm | RMSNorm |
| Positional Encoding | RoPE | RoPE |
past_key_value |
Supported (caching) | Supported (caching) |
| Sliding Window | Not supported | Supported |
| GQA | Not supported (MHA used, K=V=Q, num_key_value_heads setting) |
Supported |
| Scaled Dot Product Attention | Uses F.scaled_dot_product_attention |
Uses F.scaled_dot_product_attention |
| Enhanced RoPE Caching | Efficiently manages cos and sin caches in the forward method using _set_cos_sin_cache, updates when necessary, optimizes RoPE application logic during incremental decoding with apply_rotary_pos_emb_single, minimizing redundant calculations. |
Creates cos_cached and sin_cached in the _set_cos_sin_cache method, uses them in the forward method, applies different position IDs to queries and keys in apply_rotary_pos_emb. |
| Attention Mask Optimization | Uses scaled_dot_product_attention function, efficiently combines attention_mask and causal_mask, reduces unnecessary operations. |
Uses scaled_dot_product_attention function, handles attention_mask and sliding_window_mask. |
return_dict |
Returns output flexibly and clearly with return_dict. |
Returns output using return_dict. |
| Weight Tying | Ties embedding weights and output layer weights in the post_init method to reduce parameters and improve performance. |
No explicit mention of weight tying. |
Key Improvements * Multi-Head Attention (MHA): Instead of Mistral’s GQA (Grouped-Query Attention), a standard MHA is used. Phi-3 Mini demonstrates that it can achieve sufficient performance without GQA. * Improved RoPE Caching: Efficiently manages cos and sin caches within the forward method using _set_cos_sin_cache to update only when necessary. Additionally, optimizes RoPE application during incremental decoding by utilizing the apply_rotary_pos_emb_single function to minimize redundant calculations. * Attention Mask Optimization: Combines attention_mask and causal_mask efficiently while using the scaled_dot_product_attention function to reduce unnecessary computations. * Weight Tying: Binds embedding weights and output layer weights in post_init to reduce parameters and improve performance.
Now, let’s take a closer look at the key components of the simple_phi3 model.
The PhiMiniConfig class defines the model’s hyperparameters, following Phi-3 Mini’s settings, which have already been detailed in Mistral and will be omitted here.
The PhiMiniRMSNorm class implements RMSNorm (Root Mean Square Layer Normalization) and is identical to Mistral’s implementation.
The PhiMiniRotaryEmbedding class implements RoPE (Rotary Positional Embedding). While similar to Mistral’s MistralRotaryEmbedding, it includes key improvements to maximize caching efficiency:
forward Method:
cos_cached and sin_cached within the forward method, utilizing already computed values when available._set_cos_sin_cache when the sequence length exceeds max_seq_len_cached, preventing unnecessary cache creation and maximizing reuse of computed values.max_seq_len_cached, cos_cached, sin_cached Instance Variables:
max_seq_len_cached: Stores the maximum sequence length cached so far.cos_cached and sin_cached: Store pre-computed cosine and sine values.forward method calls, enhancing efficiency.apply_rotary_pos_emb_single: Enables the application of RoPE to only the new token during incremental decoding that uses past_key_value, avoiding redundant calculations since previous tokens’ RoPE results are already stored in past_key_value.These improvements significantly enhance the efficiency of RoPE operations, particularly offering performance advantages when processing long sequences or generating text.
The PhiMiniAttention class implements the attention mechanism of Phi-3 Mini. It uses a general Multi-Head Attention (MHA) instead of Mistral’s GQA, but optimizes the RoPE application method to improve efficiency.
past_key_value.
past_key_value is not present (general case): generate position IDs for the entire sequence (0 to q_len - 1).past_key_value is present (incremental decoding): generate position IDs for new tokens (past_len to past_len + q_len - 1) and for the entire key sequence (0 to past_len + q_len - 1).apply_rotary_pos_emb_single function when past_key_value is present (incremental decoding).past_key_value to speed up inference, similar to Mistral.rotate_half, apply_rotary_pos_emb, apply_rotary_pos_emb_singlerotate_half: A helper function required for RoPE implementation, identical to Mistral.apply_rotary_pos_emb: Apply RoPE to query (q) and key (k) tensors. Unlike Mistral, it only receives one position_ids (applied equally to queries and keys).apply_rotary_pos_emb_single: Apply RoPE to the input tensor x (query or key) in incremental decoding situations using past_key_value.The PhiMiniMLP class implements a FeedForward network, which is similar to Mistral but uses the GELU activation function.
The PhiMiniDecoderLayer class uses a Pre-Norm structure and Residual Connection, identical to Mistral.
The PhiMiniModel class constructs the entire Phi-3 Mini model, similar to Mistral.
The PhiMiniForCausalLM class adds a language modeling head (lm_head) to the PhiMiniModel.
post_init Method:
self.transformer.embed_tokens.weight) and output layer weights (self.lm_head.weight). This reduces the number of parameters, prevents overfitting, and generally improves performance.generate Function: A function for text generation. When past_key_values is present, it passes only the last token to forward() instead of the entire sequence to address RoPE-related issues during incremental decoding.simple_phi3 Model Example: Complex Formula CalculationAs a practical example of the simple_phi3 model discussed in Section 9.8.1, we will test its ability to calculate complex formulas. Through this example, we will verify whether a small language model (SLM) like Phi-3 Mini can process not only simple addition and subtraction but also multiplication and complex formulas with parentheses, and analyze its performance and limitations.
The location of the example code is chapter_09/phi3/examples/train_math.py.
Significance of the Example
Training Data Format
We generated complex arithmetic data in the following format using the create_complex_arithmetic_data function:
expression=result<eos> (e.g., (12+7)*3=57<eos>, 12+7*3=33<eos>)Training Results
Sample 1: 41*8-2=326<eos>
Sample 2: 15+(9*48)=447<eos>
Sample 3: 35-6+38=67<eos>
Sample 4: 6*14*15=1260<eos>
Sample 5: 36*(13*46)=21528<eos>
...(training log omitted)...
Prompt: '23-23-50=' --> generated result: '23-23-50=-50' (answer: 23-23-50=-50<eos>)
Prompt: '39-46-15=' --> generated result: '39-46-15=-22' (answer: 39-46-15=-22<eos>)
Prompt: '(33-30)+30=' --> generated result: '(33-30)+30=33' (answer: (33-30)+30=33<eos>)
Prompt: '30+14*27=' --> generated result: '30+14*27=412' (answer: 30+14*27=408<eos>)Result Analysis
simple_phi3 model learned the operation rules of complex formulas well.Conclusion
The simple_phi3 model, with only about 120,000 parameters, showed a high accuracy rate of around 80% in complex formula calculations. This means that it has learned complex rules such as parenthesis handling and operation order to a significant extent. Compared to large language models (LLMs) with billions of parameters, simple_phi3 shows impressive results despite its extremely small size (0.12M).
import torch
import random
from dldna.chapter_09.phi3.examples.train_complex_math import PhiMiniConfig, PhiMiniForCausalLM, ComplexArithmeticDataset, train, create_complex_arithmetic_data, create_tokenizer, create_reverse_tokenizer, generate_text
from torch.utils.data import DataLoader
random.seed(42)
torch.manual_seed(42)
device = "cuda" if torch.cuda.is_available() else "cpu"
# Hyperparameters
num_samples = 100000 # Sufficiently large amount of data
max_value = 50 # Maximum value of operands (for slightly complex calculations)
seq_length = 30 # Complex arithmetic problems can have somewhat long expressions
batch_size = 128
epochs = 30
learning_rate = 1e-3
# Data generation
complex_data = create_complex_arithmetic_data(num_samples, max_value)
print("Training data examples:")
for i in range(5):
print(f"Sample {i+1}: {complex_data[i]}")
# Create tokenizer and reverse tokenizer
tokenizer = create_tokenizer()
reverse_tokenizer = create_reverse_tokenizer(tokenizer)
updated_vocab_size = len(tokenizer)
# Configure Dataset and DataLoader
dataset = ComplexArithmeticDataset(complex_data, seq_length, tokenizer)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# PhiMini Model Configuration
config = PhiMiniConfig(
vocab_size=updated_vocab_size,
hidden_size=64, # Small model size for experimentation
intermediate_size=128,
num_hidden_layers=3,
num_attention_heads=8,
num_key_value_heads=8, # K=V=Q
max_position_embeddings=128,
use_cache=False,
use_return_dict=True,
)
config.pad_token_id = tokenizer["<pad>"]
config.eos_token_id = tokenizer["<eos>"]
# Create PhiMini For CausalLM Model
model = PhiMiniForCausalLM(config).to(device)
print("Total Trainable Parameters:", sum(p.numel() for p in model.parameters() if p.requires_grad))
# weight tying (share weights between embedding and lm_head)
model.lm_head.weight = model.transformer.embed_tokens.weight
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs, eta_min=1e-5)
# Model Training
print("Start training...")
train(model, dataloader, optimizer, scheduler, epochs, device)
# Save Model
save_path = "phimini_complex_math.pt"
torch.save(model.state_dict(), save_path)
print(f"Model saved: {save_path}")
# Load Saved Model (create a new model object before testing and load_state_dict)
loaded_model = PhiMiniForCausalLM(config).to(device)
loaded_model.load_state_dict(torch.load(save_path, map_location=device))
loaded_model.eval()
# Generate and Print Results with Test Set, Calculate Accuracy
print("\nTest sample generation results:")
test_samples = random.sample(complex_data, 10)
correct_count = 0
for sample in test_samples:
prompt = sample.split('=')[0] + '='
generated = generate_text(loaded_model, prompt, tokenizer, reverse_tokenizer, seq_length, device, temperature=0.1) # Reduce temperature for testing
answer = sample.split('=')[1].replace('<eos>', '')
if generated.split('=')[1] == answer:
correct_count += 1
print(f"Prompt: '{prompt}' --> Generated result: '{generated}' (Correct answer: {sample})")
accuracy = (correct_count / len(test_samples)) * 100
print(f"\nOverall accuracy: {accuracy:.2f}% ({correct_count}/{len(test_samples)})")Training data examples:
Sample 1: 41*8-2=326<eos>
Sample 2: 15+(9*48)=447<eos>
Sample 3: 35-6+38=67<eos>
Sample 4: 6*14*15=1260<eos>
Sample 5: 36*(13*46)=21528<eos>
Total Trainable Parameters: 126208
Start training...
Epoch 1/30, Avg Loss: 0.7439, LR: 0.000997
Epoch 2/30, Avg Loss: 0.6393, LR: 0.000989
Epoch 3/30, Avg Loss: 0.6139, LR: 0.000976
Epoch 4/30, Avg Loss: 0.5919, LR: 0.000957
Epoch 5/30, Avg Loss: 0.5825, LR: 0.000934
Epoch 6/30, Avg Loss: 0.5753, LR: 0.000905
Epoch 7/30, Avg Loss: 0.5696, LR: 0.000873
Epoch 8/30, Avg Loss: 0.5649, LR: 0.000836
Epoch 9/30, Avg Loss: 0.5599, LR: 0.000796
Epoch 10/30, Avg Loss: 0.5558, LR: 0.000753
Epoch 11/30, Avg Loss: 0.5522, LR: 0.000706
Epoch 12/30, Avg Loss: 0.5479, LR: 0.000658
Epoch 13/30, Avg Loss: 0.5443, LR: 0.000608
Epoch 14/30, Avg Loss: 0.5409, LR: 0.000557
Epoch 15/30, Avg Loss: 0.5370, LR: 0.000505
Epoch 16/30, Avg Loss: 0.5339, LR: 0.000453
Epoch 17/30, Avg Loss: 0.5307, LR: 0.000402
Epoch 18/30, Avg Loss: 0.5280, LR: 0.000352
Epoch 19/30, Avg Loss: 0.5242, LR: 0.000304
Epoch 20/30, Avg Loss: 0.5217, LR: 0.000258
Epoch 21/30, Avg Loss: 0.5189, LR: 0.000214
Epoch 22/30, Avg Loss: 0.5161, LR: 0.000174
Epoch 23/30, Avg Loss: 0.5137, LR: 0.000137
Epoch 24/30, Avg Loss: 0.5120, LR: 0.000105
Epoch 25/30, Avg Loss: 0.5101, LR: 0.000076
Epoch 26/30, Avg Loss: 0.5085, LR: 0.000053
Epoch 27/30, Avg Loss: 0.5073, LR: 0.000034
Epoch 28/30, Avg Loss: 0.5062, LR: 0.000021
Epoch 29/30, Avg Loss: 0.5055, LR: 0.000013
Epoch 30/30, Avg Loss: 0.5050, LR: 0.000010
Model saved: phimini_complex_math.pt
Test sample generation results:
Prompt: '23-23-50=' --> Generated result: '23-23-50=-50' (Correct answer: 23-23-50=-50<eos>)
Prompt: '39-46-15=' --> Generated result: '39-46-15=-22' (Correct answer: 39-46-15=-22<eos>)
Prompt: '(33-30)+30=' --> Generated result: '(33-30)+30=33' (Correct answer: (33-30)+30=33<eos>)
Prompt: '30+14*27=' --> Generated result: '30+14*27=408' (Correct answer: 30+14*27=408<eos>)
Prompt: '(13-22)-18=' --> Generated result: '(13-22)-18=-27' (Correct answer: (13-22)-18=-27<eos>)
Prompt: '9-15+12=' --> Generated result: '9-15+12=6' (Correct answer: 9-15+12=6<eos>)
Prompt: '28*(3+31)=' --> Generated result: '28*(3+31)=960' (Correct answer: 28*(3+31)=952<eos>)
Prompt: '24*(12+1)=' --> Generated result: '24*(12+1)=320' (Correct answer: 24*(12+1)=312<eos>)
Prompt: '(1-33)+26=' --> Generated result: '(1-33)+26=-6' (Correct answer: (1-33)+26=-6<eos>)
Prompt: '24+47+6=' --> Generated result: '24+47+6=77' (Correct answer: 24+47+6=77<eos>)
Overall accuracy: 80.00% (8/10)In Chapter 9, we followed the journey of Transformer development from 2017, when the Transformer architecture was first introduced in the seminal paper “Attention is All You Need,” to the present day in 2025, focusing on the core drivers of efficiency and scalability.
Early Transformers showed remarkable performance but faced fundamental limitations due to the rapidly increasing computational cost and memory usage with sequence length. Chapter 9 delved into the relentless efforts to overcome these constraints, including software-based approaches (Section 9.2), the combination of hardware and software (Section 9.3), and various technical innovations for model scalability (Section 9.4). From implementation examples such as RoPE and FlashAttention (Section 9.5) to architecture analyses of state-of-the-art models like Mistral, Gemma, and Phi-3 Mini (Sections 9.6, 9.7, and 9.8), we explored both theoretical and practical aspects to shed light on efficient Transformer architectures.
Thanks to these technical advancements, Transformers have become a powerful tool that can understand longer contexts, solve more complex problems, and be applied to a wider range of fields. We can see how efficiency and scalability played a crucial role in the growth of Transformers beyond simple language models to become a core driving force for AI technology development.
Of course, there are still challenges to be addressed. The increase in energy consumption due to model enlargement, bias and toxicity issues, and model interpretability problems are significant challenges that we must overcome in the future. Research toward safer, more reliable, and human-collaborative AI systems will continue.
In Chapters 10 and 11, we will embark on a journey into the world of multimodal integration, where Transformers go beyond text to incorporate images, audio, video, and other types of data. Multimodal models that fuse information from multiple modalities can achieve richer and more powerful representations, enabling more complex inferences. Focusing on pioneering models like ViT, CLIP, DALL-E, Stable Diffusion, Flamingo, GATO, and Gemini, which combine text and images, we will explore multimodal attention mechanisms and their infinite application possibilities. The innovations in efficiency and scalability discussed in Chapter 9 will serve as a solid foundation for the future of multimodal Transformers, which will be unfolded in Chapters 10 and 11.
In the development of large language models (LLMs), Mixture of Experts (MoE) has emerged as a framework that innovatively balances model capacity and computational efficiency. MoE operates by combining multiple “expert” networks and selectively activating the appropriate expert through a gating network based on the input. Here, we deeply dissect the core mechanism of MoE and systematically organize the extension theory reflecting the latest research trends.
Expert Networks: There are N expert networks \(\{E_i\}_{i=1}^N\), typically composed of Feedforward Neural Networks (FFNs). Each expert takes an input \(x\) and generates an output \(E_i(x)\).
Gating Network: The gating network \(G\) takes an input \(x\) and outputs weights (probabilities) for each expert. These weights indicate which expert is most suitable for the input \(x\). The output of the gating network \(G(x)\) is an N-dimensional vector, where each element \(G(x)_i\) represents the weight for the ith expert.
Final Output: The final output \(y\) of the MoE model is calculated as the weighted sum of the expert outputs.
\(y = \sum_{i=1}^{N} G(x)_i E_i(x)\)
When reinterpreting the MoE system as a probabilistic graphical model, the joint distribution of observed data \(\mathbf{x}\) and latent variables \(\mathbf{z}\) (expert selection indicators) is modeled as follows:
\(p(\mathbf{x}, \mathbf{z}|\theta) = p(\mathbf{z}|\theta_g)p(\mathbf{x}|\mathbf{z},\theta_e)\)
where \(\theta_g\) represents the parameters of the gating network, and \(\theta_e\) represents the parameters of the expert networks. In the variational inference framework, the Evidence Lower Bound (ELBO) is derived as:
\(\mathcal{L}(\theta, \phi) = \mathbb{E}_{q_\phi(\mathbf{z}|\mathbf{x})}[\log p_\theta(\mathbf{x}|\mathbf{z})] - D_{KL}(q_\phi(\mathbf{z}|\mathbf{x}) \parallel p(\mathbf{z}))\)
This approach redefines the MoE learning process within a Bayesian inference framework, providing a theoretical foundation for knowledge partitioning between experts. Specifically, the Gumbel-Softmax reparameterization technique enables the application of gradient descent by approximating the discrete expert selection process with a continuous one.
\(\mathbf{z} = \text{softmax}((\log \boldsymbol{\pi} + \mathbf{g})/\tau)\)
where \(\mathbf{g}\) represents Gumbel noise, and \(\tau\) is the temperature parameter.
DeepSeek-V2 introduced Multi-Head Latent Attention (MLA), which greatly reduces the Key-Value cache [5, 6]. This is achieved through an approach that dichotomizes the expert hierarchy into spatial partitioning and functional partitioning.
\(E_i(\mathbf{x}) = \sum_{h=1}^H W_{h,i}^o \cdot \text{GeLU}(W_{h,i}^k \mathbf{x} \oplus W_{h,i}^v \mathbf{x})\)
Within each expert, attention heads play the role of independent sub-experts, maximizing parameter efficiency through shared basis matrices.
The Mixtral 8x7B model introduced a mechanism that dynamically reconfigures the expert connection structure based on the input data. The router network has evolved from simple expert selection to a graph neural network that adjusts the connection intensity between experts.
\(A_{ij}^{(l)} = \sigma(f_\phi(\mathbf{h}_i^{(l)}, \mathbf{h}_j^{(l)}))\)
Here, \(A_{ij}\) represents the connection weight between experts \(i\) and \(j\), enabling multi-scale feature extraction through hierarchical attention mechanisms.
Balanced Optimization: To address the expert load imbalance problem, dual decomposition techniques are introduced, and Lagrange multiplier methods are used to explicitly constrain the standard deviation of expert utilization.
\(\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{task}} + \lambda \sum_{i=1}^N (\mathbb{E}[u_i] - \bar{u})^2\)
Here, \(u_i\) represents the utilization rate of the \(i\)th expert, and \(\bar{u}\) represents the target average utilization rate.
Multi-layered Knowledge Distillation: Hierarchical knowledge distillation reflecting the hierarchical structure of MoE is proposed. \(\mathcal{L}_{KD} = \sum_{l=1}^{L}\alpha_{l}D_{KL}(g^{\text{teacher}}_{l} || g^{\text{student}}_{l})\) By minimizing the KL divergence of the gating distribution \(g_{l}\) at each MoE layer \(l\), the transfer of expert-specialized knowledge is made possible.
NVIDIA H100 Tensor Core GPU introduces a dedicated Sparse Execution Unit for MoE, accelerating Top-k routing operations. * Dynamic Warp Control: Independently manages execution flow for each expert group * Hierarchical Shared Memory: Optimizes intermediate result sharing between experts * Asynchronous Model Parallelism: Minimizes latency when executing distributed experts
Recent research has developed a technique to reduce communication bandwidth by quantizing expert parameters to 4 bits [5]. It applies differential quantization. \(\Delta W_{i} = \text{sign}(W_{i}-\hat{W})\cdot 2^{\lfloor \log_{2}|W_{i}-\hat{W}|\rfloor}\) where \(\hat{W}\) represents the shared base matrix, and only the deviation of each expert is quantized to minimize precision loss.
In 2025, Google DeepMind’s latest research proposed CES-MoE, which models experts as distributions in a continuous space rather than discrete objects. It utilizes a Brownian motion-based expert diffusion model. \(dE_t = \mu(E_t,t)dt + \sigma(t)dW_t\)
This approach models the gradual evolution of expert characteristics and shows excellent performance in dynamic domain adaptation.
Next-generation MoE architectures are exploring the replacement of expert networks with neural ordinary differential equations (ODEs) \(\frac{d\mathbf{h}(t)}{dt} = f_\theta(\mathbf{h}(t), t)\)
This allows for modeling the temporal evolution characteristics of experts, achieving performance improvements in long-horizon inference tasks.
Naver’s HyperClova X-MoE system deployed 1,024 experts through hierarchical clustering.
OpenAI’s GPT-4o applied MoE to multi-modal learning.
\(\mathbf{h}_{\text{fused}} = \sum_{i=1}^N G(\mathbf{x}_{\text{text}} \oplus \mathbf{x}_{\text{image}})_i E_i(\mathbf{x}_{\text{text}}, \mathbf{x}_{\text{image}})\)
Operating experts in the text-image joint embedding space to improve cross-modal inference performance.
References:
[1] Fedus, W., Zoph, B., & Shazeer, N. (2021). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv preprint arXiv:2101.03961.
[2] Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., & Dean, J. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv preprint arXiv:1701.06538.
[3] Jacobs, R. A., Jordan, M. I., Nowlan, S. J., & Hinton, G. E. (1991). Adaptive mixtures of local experts. Neural computation, 3(1), 79-87.
[4] NVIDIA Developer Blog. (2024). Applying Mixture of Experts in LLM Architectures. https://developer.nvidia.com/blog/applying-mixture-of-experts-in-llm-architectures/
[5] DeepSeek-V2 related materials: * Modu Labs Blog. https://modulabs.co.kr/blog/deepseek-r1-introduction * HyperLab. https://hyperlab.hits.ai/blog/ai-deepseek * Wikidocs. https://wikidocs.net/275230 [6] Chung, E. (2023). Next-Generation Architectures after Trend Transformer - MoE, SSM, RetNet, V-JEPA. Velog. https://velog.io/@euisuk-chung/%ED%8A%B8%EB%A0%8C%EB%93%9C-%ED%8A%B8%EB%A0%8C%EC%8A%A4%ED%8F%AC%EB%A8%B8-%EC%9D%B4%ED%9B%84%EC%9D%98-%EC%B0%A8%EC%84%B8%EB%8C%80-%EC%95%84%ED%82%A4%ED%85%8D%EC%B3%90-MoE-SSM-RetNet-V-JEPA
[7] The Moonlight. (2024). GG MoE vs MLP on Tabular Data. https://www.themoonlight.io/ko/review/gg-moe-vs-mlp-on-tabular-data
[8] Unite.AI. (2024). Mistral AI’s Latest Mixture-of-Experts (MoE) 8x7B Model. https://www.unite.ai/ko/mistral-ais-latest-mixture-of-experts-moe-8x7b-model/
[9] Turing Post (2024) MS EUREKA Benchmark. https://turingpost.co.kr/p/ms-eureka-benchmark
Basic Problems
Applied Problems
In-Depth Problems
Attention Mechanism Computational Complexity: The attention mechanism calculates the relationship between each token pair. When the sequence length is n, for each of the n tokens, it needs to calculate its relationship with the other (n-1) tokens. Therefore, a total of n * (n-1) ≈ n² operations are required, making the computational complexity O(n²).
FlashAttention Optimization: FlashAttention maximizes the use of GPU SRAM (fast memory). It divides the input into small blocks, loads them into SRAM, performs attention operations in block units, and then writes the results back to HBM (slow memory). This reduces the number of HBM accesses, minimizes memory I/O, and increases computation speed.
MQA vs. GQA:
PagedAttention & vLLM: PagedAttention stores the KV cache in non-contiguous memory blocks (pages) using the operating system’s paging concept. vLLM utilizes PagedAttention to reduce memory waste, dynamically manages the KV cache, and improves inference speed and throughput.
Hierarchical Attention vs. Recurrent Memory Transformer:
Text Classification Code: (Code writing omitted) Refer to the example code in Section 9.5, replace nn.TransformerEncoderLayer with the efficient_encoder function, apply FlashAttention, Pre-LN, and Gradient Checkpointing. Add dataset loading and preprocessing, model training, and evaluation codes.
Number-English Word Conversion: (Code writing omitted) Load the Simple Mistral model, prepare training data consisting of number-English word pairs, train the model, and evaluate its performance on test data (e.g., BLEU score).
Natural Language-SQL Conversion: (Code writing omitted) Load the Simple Mistral model, prepare training data consisting of natural language question and SQL query pairs, train the model, and evaluate its performance on test data (e.g., accuracy, executability).
Constitutional AI Proposal: (Implementation omitted) Constitutional AI defines a series of rules (constitution) for model responses and evaluates or modifies them based on these rules. To apply this to transformer models, one can: (1) define ethical/safety rules, (2) add a separate module to evaluate model outputs, or (3) use loss functions reflecting the rules during fine-tuning.
FlashAttention Mathematical Analysis: (Mathematical analysis omitted) FlashAttention reduces the number of HBM accesses through block-based operations. While traditional attention requires O(n²) memory access, FlashAttention requires only O(n²/B) HBM access when the block size is B (B is limited by the GPU SRAM size).
KV Cache Size Reduction Methods:
New Attention Mechanism Proposal: (Idea proposal)
Constitutional AI Limitations and Overcoming Measures: